
Georg Cantor
Cantormængden er et af mange eksempler på, hvor forunderligt og besynderligt de reelle tal opfører sig. Dette indlæg er skrevet med udgangspunkt i et oplæg fra Horia Cornean – jeg har bedt kollegerne om hjælp til ideer, så mine kæpheste ikke bliver de eneste i stalden…
Det er nemt nok at definere Cantormængden. Først lidt notation: For to reelle tal, a,b, er [a,b] det lukkede interval mellem a og b, altså de relle tal x, som opfylder  .
.
(a,b) er det åbne interval, altså de reelle tal, der opfylder  . Hvis
. Hvis  , er der ingen tal i (a,b). Når
, er der ingen tal i (a,b). Når  har intervallet [a,b] længde b-a og intervallerne (a,b), (a,b], [a,b) har også længde b-a. Det er altså ligemeget, om endepunkterne er med. Længder kan lægges sammen, så længden af [2,3]U (5,7) er 1+2=3. En nulmængde er en delmængde med længde 0.
har intervallet [a,b] længde b-a og intervallerne (a,b), (a,b], [a,b) har også længde b-a. Det er altså ligemeget, om endepunkterne er med. Længder kan lægges sammen, så længden af [2,3]U (5,7) er 1+2=3. En nulmængde er en delmængde med længde 0.
Start med det lukkede interval [0,1], og fjern så delmængder som følger:
Fjern først det åbne interval (1/3,2/3) . Det der står tilbage er [0,1/3] U [2/3,1]. Vi deler nu de to resterende intervaller i tre lige dele og fjerner de to åbne intervaller i midten.
Det som står tilbage er:
[0,1/9] U [2/9,1/3] U [2/3,7/9] U [8/9,1]

Cantormængden er det sorte, der bliver tilbage. Her er fjernet de første 7 skridt.
Den samlede længde af de tre intervaller, vi har fjernet indtil nu, er 1/3 + 2/9. Vi fortsætter med den same procedure ved at dele hvert interval i tre og fjerne de åbne intervaller som står i midten.
Efter den tredje runde, er den totale længde af det, vi har fjernet, ^2)") . Efter
. Efter  trin har vi fjernt en åben mængde af samlet længde
trin har vi fjernt en åben mængde af samlet længde ^2+\ldots +(2/3)^N)") . Den følge går mod 1 når
. Den følge går mod 1 når  går mod uendelig, dvs. det som står tilbage (Cantor mængden) har “længde” nul. (Læsere, der er bekendt med den geometriske række vil vide, at
går mod uendelig, dvs. det som står tilbage (Cantor mængden) har “længde” nul. (Læsere, der er bekendt med den geometriske række vil vide, at  når |c|<1 – brug dette med c=2/3. Andre læsere kan overveje, at
når |c|<1 – brug dette med c=2/3. Andre læsere kan overveje, at (1+c+c^2+\ldots + c^N)=1-c^{N+1}") , så
, så  . Hvis |c|<1 går
. Hvis |c|<1 går  mod 0, når N går mod uendelig og så går
mod 0, når N går mod uendelig og så går  mod
mod  )
)
Hvert element “A” i Cantor mængden kan entydigt identificeres med et tal i intervallet [9,10] af typen a=9,18118188…; lad os forklare hvad det betyder: Hvis den første decimal efter kommaet af “a” er 1, betyder det, at A ligger i [0,1/3]. Hvis den første decimal efter kommaet af “a” er 8, så betyder det, at A tilhører intervallet [2/3,1]. Hvis de første to decimaler af “a” er 9,18 betyder det, at A er et punkt i [2/9,1/3]. Når “a” starter med 9,88 betyder det, at A er et punkt i [8/9,1]. Og så videre. Man kan tænke på, at tallene 1 og 8 siger, om man skal til venstre eller højre for det næste midterstykke, der er fjernet. Til hvert punkt i intervallet [9,10] på formen ovenfor er der præcis et element i Cantormængden. Og omvendt: Start med et element A i Cantormængden, så er det i enten [0,1/3] eller [2/3,1] – det giver første decimal. Den næste decimal er bestemt ved, om A ligger til venstre eller højre for den midterste tredjedel, der er fjernet i næste omgang osv.
Cantor mængden kan ikke tælles. Beviset bruger Cantors diagonalargument: Vi skal vise, at mængden at tal på formen 9,11881881… som ovenfor ikke kan tælles. Men først en definition
En mængde M er tællelig, hvis der kan laves en afbildning fra de naturlige tal  , altså “tælletallene”, 1,2,3,4,… til M, som rammer alle elementer i M, m.a.o.
, altså “tælletallene”, 1,2,3,4,… til M, som rammer alle elementer i M, m.a.o.  surjektiv. (Ikke alle vil kalde en endelig mængde for tællelig. Dem har vi med i denne definition. Man kan også lade funktionen gå den anden vej – fra M til de naturlige tal. Så skal man forlange, den er injektiv.)
surjektiv. (Ikke alle vil kalde en endelig mængde for tællelig. Dem har vi med i denne definition. Man kan også lade funktionen gå den anden vej – fra M til de naturlige tal. Så skal man forlange, den er injektiv.)
Antag nu, at vi har en funktion  tal på formen ovenfor. Vi skal vise, at det ikke kan passe. Skriv tallene i rækkefølge, f(1), f(2),….. under hinanden:
tal på formen ovenfor. Vi skal vise, at det ikke kan passe. Skriv tallene i rækkefølge, f(1), f(2),….. under hinanden:
=9,a_{11}a_{12}a_{13}a_{14}\ldots a_{1k}\ldots")
=9,a_{21}a_{22}a_{23}a_{24}\ldots a_{2k}\ldots")
=9,a_{31}a_{32}a_{33}a_{34}\ldots a_{3k}\ldots")
=9,a_{n1}a_{n2}a_{n3}a_{n4}\ldots a_{nk}\ldots")
Nu laver jeg et tal, som ikke er talt med:  givet som følger: Hvis
givet som følger: Hvis  , så er
, så er  og hvis $a_{kk}=8$, så er
og hvis $a_{kk}=8$, så er  . Nu kan vi se, at $b$ ikke er med i billedet af f, for
. Nu kan vi se, at $b$ ikke er med i billedet af f, for  og derfor er
og derfor er ") for noget n.
for noget n.
Det vil sige, vi har bygget en mængde med længde nul som ikke er tællelig. Cantors mængde er også lukket, fordi det, vi fjerner fra [0,1], er en (tællelig) forening af åbne intervaller. Ifølge Heine-Borels sætning er Cantors mængde kompakt fordi den er både lukket og begrænset.
Cantors mængde har ingen indre punkter, fordi den tællelige forening af åbne intervaller som vi har fjernet indeholder punkter som ligger arbitrært tæt på ethvert punkt af Cantor mængden. Det kan I tænke over.
 Start med det lukkede interval [0,1] og fjern den midterste (åbne) fjerdedel. Så har vi [0,3/8] U [5/8,1] tilbage. Nu fjerne vi den midterste sekstendedel fra hvert af de to intervaller og har så
Start med det lukkede interval [0,1] og fjern den midterste (åbne) fjerdedel. Så har vi [0,3/8] U [5/8,1] tilbage. Nu fjerne vi den midterste sekstendedel fra hvert af de to intervaller og har så![[0,\frac{5}{32}]\cup[\frac{7}{32},\frac{3}{8}]\cup [\frac{5}{8},\frac{25}{32}]\cup[\frac{27}{32},1]](https://s0.wp.com/latex.php?latex=%5B0%2C%5Cfrac%7B5%7D%7B32%7D%5D%5Ccup%5B%5Cfrac%7B7%7D%7B32%7D%2C%5Cfrac%7B3%7D%7B8%7D%5D%5Ccup+%5B%5Cfrac%7B5%7D%7B8%7D%2C%5Cfrac%7B25%7D%7B32%7D%5D%5Ccup%5B%5Cfrac%7B27%7D%7B32%7D%2C1%5D&bg=ffffff&fg=000000&s=0 "[0,\frac{5}{32}]\cup[\frac{7}{32},\frac{3}{8}]\cup [\frac{5}{8},\frac{25}{32}]\cup[\frac{27}{32},1]")






![]p-\varepsilon,p+\varepsilon[](https://s0.wp.com/latex.php?latex=%5Dp-%5Cvarepsilon%2Cp%2B%5Cvarepsilon%5B&bg=ffffff&fg=000000&s=0 "]p-\varepsilon,p+\varepsilon[")


(1+2^s+2^{2s}+2^{3s}+\cdots +2^{(r-1)s})") , så hvis hverken r eller s er 1, har vi en faktorisering i ikke-trivielle faktorer.
, så hvis hverken r eller s er 1, har vi en faktorisering i ikke-trivielle faktorer. altid har a=2 og p et primtal. Hvorfor? Jo, vi har lige set, at a-1 går op i
altid har a=2 og p et primtal. Hvorfor? Jo, vi har lige set, at a-1 går op i  (brug s=1 og r=k i formlen ovenfor, og sæt a ind i stedet for 2) og hvis a ikke er 2 giver det igen en ikke-triviel faktorisering.
(brug s=1 og r=k i formlen ovenfor, og sæt a ind i stedet for 2) og hvis a ikke er 2 giver det igen en ikke-triviel faktorisering.
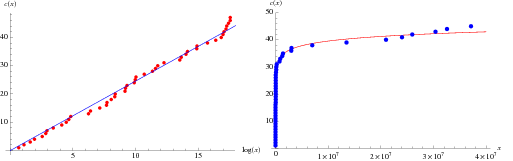
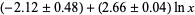 . It has been conjectured (without any particularly strong evidence) that the constant is given by
. It has been conjectured (without any particularly strong evidence) that the constant is given by 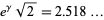 , where
, where 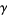 is the
is the 


") . Et kort er så en funktion
. Et kort er så en funktion =(x(\lambda,\varphi),y(\lambda,\varphi))") som tager to variable ind og giver to variable ud. For eksempel er Mercatorprojektion givet som
som tager to variable ind og giver to variable ud. For eksempel er Mercatorprojektion givet som =(\lambda,\ln(\tan(\frac{\pi}{4}+\frac{\varphi}{2})))")
=(\cos(\varphi)\cos(\lambda),\cos(\varphi)\sin(\lambda))")
=\frac{2\cos\varphi}{1+\sin\varphi}(\cos(\varphi)\cos(\lambda),\cos(\varphi)\sin(\lambda))")
 km til punktet, der er f( Nordpolen). De ligger altså på en cirkel i planen med omkreds
km til punktet, der er f( Nordpolen). De ligger altså på en cirkel i planen med omkreds  . Ser vi nu på den tilsvarende cirkel på Jorden, der altså udgøres af punkter 50 km fra Nordpolen, når man måler langs Jordoverflade, så er dens omkreds mindre end
. Ser vi nu på den tilsvarende cirkel på Jorden, der altså udgøres af punkter 50 km fra Nordpolen, når man måler langs Jordoverflade, så er dens omkreds mindre end  . (Man går lidt “ind mod midten”, mens man går fra Nordpolen langs Jordoverfladen) Så skaleringsfaktoren langs denne cirkel er ikke målestoksforholdet m. Og altså er der ikke konstant målestoksforhold.
. (Man går lidt “ind mod midten”, mens man går fra Nordpolen langs Jordoverfladen) Så skaleringsfaktoren langs denne cirkel er ikke målestoksforholdet m. Og altså er der ikke konstant målestoksforhold. og to zoner: Zone 32 med midtemeridian
og to zoner: Zone 32 med midtemeridian  og Zone 33 med midtemeridian
og Zone 33 med midtemeridian  (Bredden på zonerne er altså
(Bredden på zonerne er altså  til hver side. I virkeligheden bruger vi Zone 32 i hele landet undtagen Bornholm, men det er en anden historie.)
til hver side. I virkeligheden bruger vi Zone 32 i hele landet undtagen Bornholm, men det er en anden historie.) . DKTM har to zoner i Jylland. Kravet om lille variation af målestoksforholdet giver altså flere zoner, så man må vælge. Få zoner eller lille variation. Det er jo bøvlet at skifte kort 14 gange, når man skal køre fra Aalborg til Thisted, så det vil man gerne undgå.
. DKTM har to zoner i Jylland. Kravet om lille variation af målestoksforholdet giver altså flere zoner, så man må vælge. Få zoner eller lille variation. Det er jo bøvlet at skifte kort 14 gange, når man skal køre fra Aalborg til Thisted, så det vil man gerne undgå.



{kind=link}