Der er kvaternioner i computerspil, i flysimulatorer og i styring af robotter, der skal rotere. Hvad mon de laver der?
Kvaternionerne blev opdaget af den irske matematiker og fysiker, W.R. Hamilton. Han fik den fundamentale indsigt om dem, da han spadserede langs Royal Canal i Dublin og der sidder nu en

Mindepladen på Broome Bridge.
mindeplade på den bro, Broome Bridge hvor han efter sigende skriblede ligningerne




Kvaternioner er tal, på formen a+bi+cj+dk, hvor a, b, c, d er reelle tal og i,j,k er symboler, som kan lægges sammen som vektorer med 4 koordinaterog ganges sammen efter reglerne ovenfor. altså samme system som med de komplekse tal, men der er nu kommet j og k med. Eksempel:
+(6-2i+j-3k)=8+i-4j-2k")
(1+i+j)=2+3i-5j+k+(2+3i-5j+k)i+(2+3i-5j+k)j=2+3i-5j+k+2i+3i^2-5ji+ki+2j+3ij-5j^2+kj")

i=ki^2=-k=-ij")
Kvaternionerne er en divisionsalgebra eller et skævlegeme. I får ikke regnereglerne for divisionsalgebraernes addition og multiplikation, men jeg har brugt mange af dem ovenfor. De reelle tal og de komplekse tal er også divisionsalgebraer (med kommutativ multiplikation). Tager man udgangspunkt i addition af vektorer og forsøger at finde en multiplikation, der “matcher”, kan man kun gøre det for 

Hvad har det med computerspil og jagerfly at gøre?
En rotation i det 3-dimensionale rum kan beskrives ved en rotationsakse og en vinkel. Har man valgt sig et koordinatsystem, kan alle rotationer beskrives som en kombination af rotation om x-aksen, derefter om y-aksen og derefter om z-aksen. Man kan altså beskrive det ved de tre vinkler.
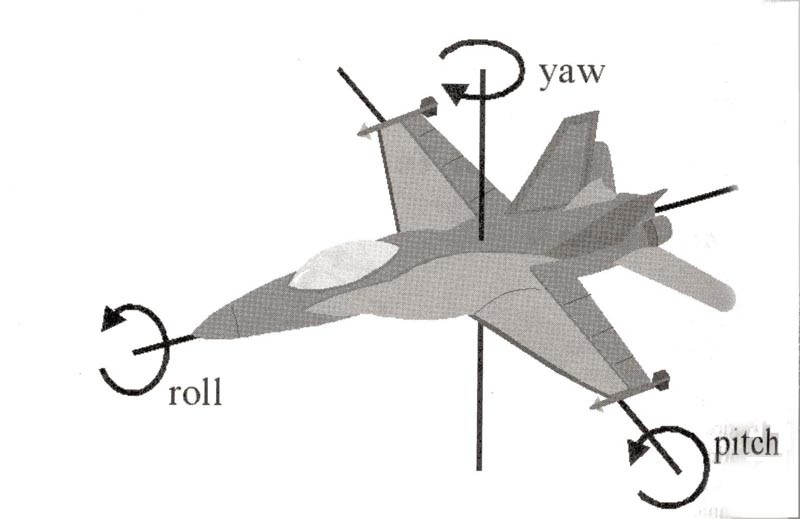
Roll, Pitch og Yaw
For jagerpiloter hedder det “roll”, pitch” og “yaw”, når man roterer om flyets egne interne akser. Man kan lege med Roll Pitch og yaw her (klik på Euler angles i øverste højre hjørne). Det er naturligvis ikke det samme som at vælge nogle faste akser, som ikke følger med flyet, men der er omregninger frem og tilbage mellem diverse systemer af vinkler og akser. Man er i øvrigt (heller) ikke enige om, hvilken akse, der roteres om først, så man skal være vågen, hvis man henter formler flere steder fra. Orienteringen af et objekt i rummet kan altså beskrives med tre vinkler, som siger, hvordan objektet er roteret i forhold til nogle faste x,y,z akser.De kaldes også Eulervinkler. Samme position kan svare til flere forskellige vinkler – hvis vi måler i radianer, gentager de sig for hver 
Så den rotation, der er lavet for at bringe flyet i en bestemt position, kan beskrives med tre vinkler, altså et punkt (u,v,w) i 



for at være sikker på, man har alle rotationer med. Kunne man mon nøjes med færre vinkler – giver nogle vinkler de samme rotationer? (Svar: Ja) Hvordan er kassen “limet sammen”? Hvordan svarer punkter i den ene ende til dem i den anden, top til bund og front til bagside? Hvordan ser det ud, når et fly ændrer sin position og går via “ydervinklerne”. M.a.o. hvordan ser det ud i vinkler, når et fly laver loop, barrel roll og andre luftakrobatiske manøvrer? Hvordan laver man en kontinuert rotation, der bringer flyet til en bestemt position i rummet, altså en kontinuert kurve i mængden af rotationer. Det er der, det bliver interessant. Og hvor beskrivelsen med Eulervinkler må give op.
Matrixbeskrivelse.
En rotation kan beskrivesmed en 3×3 matrix, hvis første søjle er koordinaterne for vektoren [1,0,0] efter rotation, anden søjle er koordinaterne for [0,1,0] efter rotation og tredje søjle er koordinaterne for [0,0,1] efter rotation. Som udgangspunkt er der 9 tal i en 3×3 matrix, men en rotations matrix skal opfylde en stribe ligninger, som kommer udfra at søjlerne har længde 1, står vinkelret på hinanden og udgør et højrehåndssystem. (Da de jo er resultatet af at rotere basisvektorerne). Rotationsmatricerne udgør delmængden SO(3) af 3×3 matricerne. Det er en 3-dimensional delmængde af det 9-dimensionale rum, som svarer til de 9 tal i en 3×3-matrix. Enhver rotationsmatrix kan skrives som et
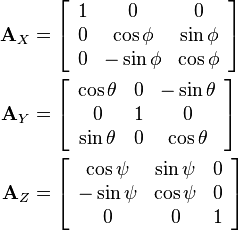
Rotationsmatricer for rotation om x,y,z aksen. Billede fra Wikipedia.
produkt af matricer, der svarer til rotation om x,y,z akserne. Altså udfra tre vinkler.
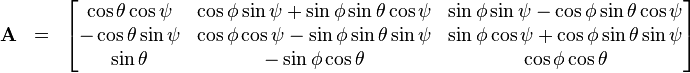
Produktet AzAyAx
Med vinklen 
& -\cos(\varphi+\psi)\\0&\cos(\varphi+\psi)&\sin(\varphi+\psi)\\1&0&0\end{array}\right)")
Jeg har brugt additionsformler for sinus og cosinus. Bemærk, at rotationen ikke afhænger af 




Dimensionen af mængden af rotationer er 3. Det er et ægte praktisk problem, som får robotter til at gøre pludselige skift på 180 grader eller (mindre alvorligt) computerspil til at se mystiske ud, når jagerfly kommer i position med eksempelvis næsen opad. (Den ubestemthed, der er i situationen, hvor man ikke kan se, hvad de to vinkler er, kan have sære effekter.) Så der er en god grund til at gøre noget ved det.
Man kan tænke på en lidt analog situation, hvor man nærmer sig Nordpolen langs en meridian, altså med fast længdegrad. man har altså breddegrad, der vokser mod 

Kvaternionerne er bedre:
Kvaternioner med længde 1 beskriver rotationer. Til en sådan kvaternion q=w+xi+yj+zk svarer rotationsmatricen
")


 instructions). The enciphering key E can thus be publicly disclosed without compromising the deciphering key D. Each user of the network can, therefore, place his enciphering key in a public directory.”
instructions). The enciphering key E can thus be publicly disclosed without compromising the deciphering key D. Each user of the network can, therefore, place his enciphering key in a public directory.” , hvor vi hele tiden tager udregner rest ved division med 11. Så vi nåede gennem alle 10 elementer.
, hvor vi hele tiden tager udregner rest ved division med 11. Så vi nåede gennem alle 10 elementer. og så starter man forfra.
og så starter man forfra. modulo q. Og fortæller hele verden, hvad Y er.
modulo q. Og fortæller hele verden, hvad Y er. modulo q. For et stort primtal q (og det skal mindst være større end tallet X), er dette problem vanskeligt – der er mange step i en computer.
modulo q. For et stort primtal q (og det skal mindst være større end tallet X), er dette problem vanskeligt – der er mange step i en computer. modulo 11. Og det har vi regnet ud ovenfor. Y=9.
modulo 11. Og det har vi regnet ud ovenfor. Y=9. modulo 11. Bob sender sit hemmelige tal m krypteret som B=
modulo 11. Bob sender sit hemmelige tal m krypteret som B= modulo 11.
modulo 11. modulo 11 og Bob udregner
modulo 11 og Bob udregner  modulo 11. De har nu begge tallet
modulo 11. De har nu begge tallet  modulo 11 =
modulo 11 = modulo 11, som er deres fælles hemmelige nøgle. De finder altså ikke ud af, hvad den andens hemmelige tal var, men finder en ny fælles hemmelighed.
modulo 11, som er deres fælles hemmelige nøgle. De finder altså ikke ud af, hvad den andens hemmelige tal var, men finder en ny fælles hemmelighed. modulo 11, får man 3 og det gør man også, hvis man udregner
modulo 11, får man 3 og det gør man også, hvis man udregner  modulo 11. Tallet 3 er nu den hemmelige nøgle. Og den har ikke kunnet opsnappes på den kanal, Alice og Bob kommunikerer over, da det ville kræve, man kendte enten n og B eller m og A. Og kun Alice hhv Bob kender n og m.
modulo 11. Tallet 3 er nu den hemmelige nøgle. Og den har ikke kunnet opsnappes på den kanal, Alice og Bob kommunikerer over, da det ville kræve, man kendte enten n og B eller m og A. Og kun Alice hhv Bob kender n og m.
 med n mindst 3, så findes en elliptisk kurve af en bestemt type. (Den er “ikke modulær”). Den kaldes en Frey-kurve.
med n mindst 3, så findes en elliptisk kurve af en bestemt type. (Den er “ikke modulær”). Den kaldes en Frey-kurve.(x+b^n)") er en elliptisk kurve, hvis vi laver den udfra et modeksempel til FSS og den er “ikke modulær”. Det fører alt for vidt at definere elliptiske kurver – men i første omgang er det en kubisk kurve – ligningen er et polynomium i x og y og graden er 3. Man får et
er en elliptisk kurve, hvis vi laver den udfra et modeksempel til FSS og den er “ikke modulær”. Det fører alt for vidt at definere elliptiske kurver – men i første omgang er det en kubisk kurve – ligningen er et polynomium i x og y og graden er 3. Man får et  -led og ikke højere. Løsningsmængden (med x og y reelle tal) er en delmængde af planen – figurerne nedenfor er eksempler på kubiske og faktisk elliptiske kurver, taget fra Mathworld. Elliptiske kurver har en sammenhæng med komplekse funktioner, som er dobbeltperiodiske – der findes to komplekse tal
-led og ikke højere. Løsningsmængden (med x og y reelle tal) er en delmængde af planen – figurerne nedenfor er eksempler på kubiske og faktisk elliptiske kurver, taget fra Mathworld. Elliptiske kurver har en sammenhæng med komplekse funktioner, som er dobbeltperiodiske – der findes to komplekse tal  , sådan at
, sådan at =f(z+k_1w_1+k_2w_2)") for alle hele tal
for alle hele tal  . De to tal
. De to tal  hvor c er et reelt tal (eller omvendt – de er lineært uafhængige over de reelle tal), så punkterne
hvor c er et reelt tal (eller omvendt – de er lineært uafhængige over de reelle tal), så punkterne  giver et gitter i den komplekse plan. funktionen f er altså bestemt ved sine værdier i et parallellogram og værdierne matcher langs kanterne. Folder man parallelogrammet sammen langs modstående kanter, får man en torus, så f er en funktion på en torus.
giver et gitter i den komplekse plan. funktionen f er altså bestemt ved sine værdier i et parallellogram og værdierne matcher langs kanterne. Folder man parallelogrammet sammen langs modstående kanter, får man en torus, så f er en funktion på en torus.
") og en vektor
og en vektor ") .
. til
til  og går som følger:
og går som følger: \cdot (-4)+\pi \cdot 7")


 . Det er første koordinat i vektoren
. Det er første koordinat i vektoren  . Og nej, det er ikke kønt, man man kan se, hvad der ganges med hvad.
. Og nej, det er ikke kønt, man man kan se, hvad der ganges med hvad.") Den er endda symmetrisk – hvis man spejler den i den diagonal, der går fra nordvest til sydøst, får man samme matrix tilbage. Det er nabomatricen for grafen
Den er endda symmetrisk – hvis man spejler den i den diagonal, der går fra nordvest til sydøst, får man samme matrix tilbage. Det er nabomatricen for grafen 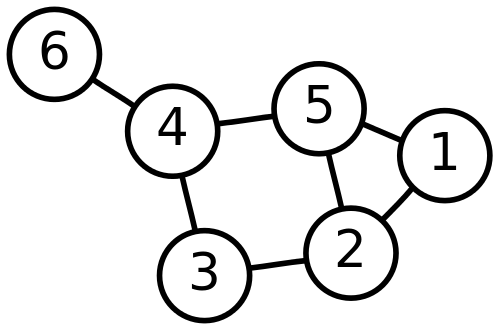
") , som indeholder information om, hvor mange stier af længde to, der er mellem knuderne. Eksempelvis er indgangen i 2.række, fjerde søjle skalarprodukt af anden række i B, som er (1,0,1,0,1,0), med fjerde søjle i B, som er (0,0,1,0,1,1). Det tæller sammen, hvor mange steder 1-tallerne matcher. Det gør de på 3. og 5. koordinat. Så der er en sti fra knude 2 til knude 4 via knude 3 og en via knude 5. Den første række (og første søjle) fortæller, hvor mange stier af længde 2, der er fra knude 1. Der er 2 stier fra 1 tilbage til 1, nemlig 1 til 5 til 1 og 1 til 2 til 1. Der er en sti til knuden 2, nemlig 1 til 5 til 2. og tilsvarende for knuderne 3, 4 og 5. Man kan ikke komme til 6 i to skridt, så der står 0. Nu kan læseren nok forudse, hvad der sker, hvis vi udregner
, som indeholder information om, hvor mange stier af længde to, der er mellem knuderne. Eksempelvis er indgangen i 2.række, fjerde søjle skalarprodukt af anden række i B, som er (1,0,1,0,1,0), med fjerde søjle i B, som er (0,0,1,0,1,1). Det tæller sammen, hvor mange steder 1-tallerne matcher. Det gør de på 3. og 5. koordinat. Så der er en sti fra knude 2 til knude 4 via knude 3 og en via knude 5. Den første række (og første søjle) fortæller, hvor mange stier af længde 2, der er fra knude 1. Der er 2 stier fra 1 tilbage til 1, nemlig 1 til 5 til 1 og 1 til 2 til 1. Der er en sti til knuden 2, nemlig 1 til 5 til 2. og tilsvarende for knuderne 3, 4 og 5. Man kan ikke komme til 6 i to skridt, så der står 0. Nu kan læseren nok forudse, hvad der sker, hvis vi udregner  etc. Men det gør jeg ikke her.
etc. Men det gør jeg ikke her.=\left(\begin{array}{cccccc}2&-1&0&0&-1&0\\-1&3&-1&0&-1&0\\0&-1&2&-1&0&0\\0&0&-1&3&-1&-1\\-1&-1&0&-1&3&0\\0&0&0&-1&0&1\end{array}\right)") I diagonalen står antal af kanter, der udgår fra den tilsvarende knude, så der står 2,3,2,3,3,1, fordi eksempelvis knude 5 er forbundet til 3 andre, mens nummer 6 kun er forbundet til en anden. Udenfor diagonalen står
I diagonalen står antal af kanter, der udgår fra den tilsvarende knude, så der står 2,3,2,3,3,1, fordi eksempelvis knude 5 er forbundet til 3 andre, mens nummer 6 kun er forbundet til en anden. Udenfor diagonalen står  , indgangene i B med negativt fortegn.
, indgangene i B med negativt fortegn.v") , hvor v=(1,1,1,1,1,1), giver 0-vektoren.
, hvor v=(1,1,1,1,1,1), giver 0-vektoren.") og vektoren (1,1,1,1,-1,-1) er en egenvektor hørende til egenværdien 0 (fordi begge hjørnematricer er Laplacematricer.) Hvis der er k sammenhængskomponenter, er der k lineært uafhængige egenvektorer hørende til egenværdien 0.
og vektoren (1,1,1,1,-1,-1) er en egenvektor hørende til egenværdien 0 (fordi begge hjørnematricer er Laplacematricer.) Hvis der er k sammenhængskomponenter, er der k lineært uafhængige egenvektorer hørende til egenværdien 0. summen af alle de differenser
summen af alle de differenser ^2") , hvor det i’te og j’te hjørne er forbundet med en kant. I eksemplet ovenfor, ville man få
, hvor det i’te og j’te hjørne er forbundet med en kant. I eksemplet ovenfor, ville man få ^2+(v1-v5)^2+(v2-v5)^2+(v2-v3)^2+(v3-v4)^2+(v4-v5)^2+(v4-v6)^2") . For en fuldstændig graf får man alle
. For en fuldstændig graf får man alle ^2")
") og her en vektor
og her en vektor ")





")
")

![[0,\frac{5}{32}]\cup[\frac{7}{32},\frac{3}{8}]\cup [\frac{5}{8},\frac{25}{32}]\cup[\frac{27}{32},1]](https://s0.wp.com/latex.php?latex=%5B0%2C%5Cfrac%7B5%7D%7B32%7D%5D%5Ccup%5B%5Cfrac%7B7%7D%7B32%7D%2C%5Cfrac%7B3%7D%7B8%7D%5D%5Ccup+%5B%5Cfrac%7B5%7D%7B8%7D%2C%5Cfrac%7B25%7D%7B32%7D%5D%5Ccup%5B%5Cfrac%7B27%7D%7B32%7D%2C1%5D&bg=ffffff&fg=000000&s=0 "[0,\frac{5}{32}]\cup[\frac{7}{32},\frac{3}{8}]\cup [\frac{5}{8},\frac{25}{32}]\cup[\frac{27}{32},1]")
 langt stykke midt i hvert af de
langt stykke midt i hvert af de  intervaller, der er tilbage. Ialt fjerner man
intervaller, der er tilbage. Ialt fjerner man  for n=1,2,3,… ialt
for n=1,2,3,… ialt
 Det er den fede (eller en af de fede) Cantormængder. Når man tænker på, at der ikke er nogen indre punkter i mængde, er det altså virkelig underligt og en lille smule rystende: Der er en total længde på
Det er den fede (eller en af de fede) Cantormængder. Når man tænker på, at der ikke er nogen indre punkter i mængde, er det altså virkelig underligt og en lille smule rystende: Der er en total længde på  , du vælger, så er der i intervallet
, du vælger, så er der i intervallet ![]p-\varepsilon,p+\varepsilon[](https://s0.wp.com/latex.php?latex=%5Dp-%5Cvarepsilon%2Cp%2B%5Cvarepsilon%5B&bg=ffffff&fg=000000&s=0 "]p-\varepsilon,p+\varepsilon[") punkter, der bliver fjernet i processen. Så hvis p ligger i den fede (eller for den sags skyld den tynde) Cantormængde, så er der ikke mulighed for at tage
punkter, der bliver fjernet i processen. Så hvis p ligger i den fede (eller for den sags skyld den tynde) Cantormængde, så er der ikke mulighed for at tage  som ikke indeholder noget fra Cantormængden (for lille nok
som ikke indeholder noget fra Cantormængden (for lille nok  . Cantormængder er intetsteds tætte. Men fylder alligevel, hvis de er fede…
. Cantormængder er intetsteds tætte. Men fylder alligevel, hvis de er fede…(1+2^s+2^{2s}+2^{3s}+\cdots +2^{(r-1)s})") , så hvis hverken r eller s er 1, har vi en faktorisering i ikke-trivielle faktorer.
, så hvis hverken r eller s er 1, har vi en faktorisering i ikke-trivielle faktorer. altid har a=2 og p et primtal. Hvorfor? Jo, vi har lige set, at a-1 går op i
altid har a=2 og p et primtal. Hvorfor? Jo, vi har lige set, at a-1 går op i  (brug s=1 og r=k i formlen ovenfor, og sæt a ind i stedet for 2) og hvis a ikke er 2 giver det igen en ikke-triviel faktorisering.
(brug s=1 og r=k i formlen ovenfor, og sæt a ind i stedet for 2) og hvis a ikke er 2 giver det igen en ikke-triviel faktorisering.
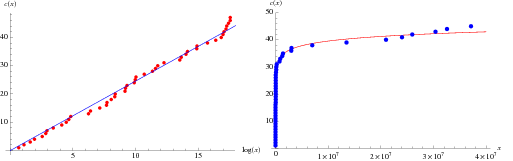
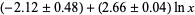 . It has been conjectured (without any particularly strong evidence) that the constant is given by
. It has been conjectured (without any particularly strong evidence) that the constant is given by 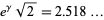 , where
, where  is the
is the 
 .
. . Hvis
. Hvis  , er der ingen tal i (a,b). Når
, er der ingen tal i (a,b). Når  har intervallet [a,b] længde b-a og intervallerne (a,b), (a,b], [a,b) har også længde b-a. Det er altså ligemeget, om endepunkterne er med. Længder kan lægges sammen, så længden af [2,3]U (5,7) er 1+2=3. En nulmængde er en delmængde med længde 0.
har intervallet [a,b] længde b-a og intervallerne (a,b), (a,b], [a,b) har også længde b-a. Det er altså ligemeget, om endepunkterne er med. Længder kan lægges sammen, så længden af [2,3]U (5,7) er 1+2=3. En nulmængde er en delmængde med længde 0.^2)") . Efter
. Efter  trin har vi fjernt en åben mængde af samlet længde
trin har vi fjernt en åben mængde af samlet længde ^2+\ldots +(2/3)^N)") . Den følge går mod 1 når
. Den følge går mod 1 når  går mod uendelig, dvs. det som står tilbage (Cantor mængden) har “længde” nul. (Læsere, der er bekendt med den geometriske række vil vide, at
går mod uendelig, dvs. det som står tilbage (Cantor mængden) har “længde” nul. (Læsere, der er bekendt med den geometriske række vil vide, at  når |c|<1 – brug dette med c=2/3. Andre læsere kan overveje, at
når |c|<1 – brug dette med c=2/3. Andre læsere kan overveje, at (1+c+c^2+\ldots + c^N)=1-c^{N+1}") , så
, så  . Hvis |c|<1 går
. Hvis |c|<1 går  mod 0, når N går mod uendelig og så går
mod 0, når N går mod uendelig og så går  mod
mod  )
) , altså “tælletallene”, 1,2,3,4,… til M, som rammer alle elementer i M, m.a.o.
, altså “tælletallene”, 1,2,3,4,… til M, som rammer alle elementer i M, m.a.o.  surjektiv. (Ikke alle vil kalde en endelig mængde for tællelig. Dem har vi med i denne definition. Man kan også lade funktionen gå den anden vej – fra M til de naturlige tal. Så skal man forlange, den er injektiv.)
surjektiv. (Ikke alle vil kalde en endelig mængde for tællelig. Dem har vi med i denne definition. Man kan også lade funktionen gå den anden vej – fra M til de naturlige tal. Så skal man forlange, den er injektiv.) tal på formen ovenfor. Vi skal vise, at det ikke kan passe. Skriv tallene i rækkefølge, f(1), f(2),….. under hinanden:
tal på formen ovenfor. Vi skal vise, at det ikke kan passe. Skriv tallene i rækkefølge, f(1), f(2),….. under hinanden:=9,a_{11}a_{12}a_{13}a_{14}\ldots a_{1k}\ldots")
=9,a_{21}a_{22}a_{23}a_{24}\ldots a_{2k}\ldots")
=9,a_{31}a_{32}a_{33}a_{34}\ldots a_{3k}\ldots")
=9,a_{n1}a_{n2}a_{n3}a_{n4}\ldots a_{nk}\ldots")
 givet som følger: Hvis
givet som følger: Hvis  , så er
, så er  og hvis $a_{kk}=8$, så er
og hvis $a_{kk}=8$, så er  . Nu kan vi se, at $b$ ikke er med i billedet af f, for
. Nu kan vi se, at $b$ ikke er med i billedet af f, for  og derfor er
og derfor er ") for noget n.
for noget n.