I dag, 26/3-2021 kan man læse, at SerumInstituttet ikke tæller dem, der er testet positivt ved kviktests med som smittede,men kun som muligt smittede. her kan man tage sin sølvpapirshat på og sige, de skjuler noget, men man man kan også finde brøkregnereglerne frem:
Der står: “45 procent – altså næsten hver andet – positive testsvar fra lyntest er forkert. Det er det, der kaldes falsk positive svar.”
Henrik Ullum siger i det indslag, at der udaf 1000 raske vil være 2-4, der tester positivt.
De to tal er hhv. den positivt prædiktive værdi. Hvis man tester positivt, hvad er så sandsynligheden for, at man er smittet. Den er altså 55%.
De 2-4 ud af 1000 er en beskrivelse af testens specificitet: ca. 99,7% af de raske får et korrekt svar. (Det passer ikke helt med det, man tidligere har hørt om kviktets, men det er det, Ullum er citeret for her. Tidligere har Rigshospitalet sagt 99,5% )
De 55% afhænger af, hvor mange syge, der faktisk er, mens de 99,7% er en egenskab ved testen.
Testens sensitivitet er sandsynligheden for at teste positivt, når man faktisk er syg.
Lad os sige, kviktest har specificitet 99,7% og sensitivitet 70% (det er det, Rigshospitalet skriver under linket ovenfor. OBS, Jeg kender ikke de tal, Ullum bruger, så jeg gætter lidt her. Jeg tror, sensitiviteten er højere.)
Hvor kommer de positive testresultater så fra? 70% af de smittede tester positivt og 0,3% af de raske tester positivt. Vi ved også, at 55% af de positive testresultater er smittede personer. Så der er rigtig mange af de positive testresultater, der kommer fra raske personer, selvom kun 0,3% af de raske tester positivt. I kan regne videre på, hvor stor (meget lille faktisk) en andel af de testede, der så må have være smittede ved at bruge sammenhængene nedenfor. Det kaldes prævalensen og er under pandemien opgjort i incidens – antal smittede ud af 100.000.
I december var prævalensen (incidensen) højere, så andelen af positivve kviktest, som var fra raske, var lavere.
Lad os regne lidt:
Hvis incidensen er 20/100.000 (det kritiske niveau sidste sommer) så sker følgende:
0,3% af de 99980 raske tester positivt. Det er ca. 300 personer.
70% af de 20 tester positivt. Det er 14 personer.
Blandt de 314 positive er der nu 14 sandt positive og 300 falsk positive. Er man testet positivt, er der altså 14/314 risiko for, at man er positiv. Det er, hvis jeg kan regne, 4,5%
Hvis incidensen er 500 ser det sådan ud:
0,3% af de 99500 tester positivt. Det er ca. 298 personer – næsten lige så mange som før.
70 % af de 500 smittede tester positivt. Det er 350 personer.
Blandt de 648 personer, der tester positivt, er 350/648 altså smittet. Det er 54%.
Hvad med dem, der tester negativt?
Hvis incidensen er 20 har vi
99680 raske tester negativt.
6 smittede tester negativt.
Ud af de 99686 med negativ test, er 99680 faktisk raske. Det er 99,99 %
Hvis incidensen er 500 har vi
99202 raske tester negativt.
150 af de smittede tester negativt.
Blandt de 99352, der tester negativt, er 99202 raske. Det er 99,8%
Den problematik har vi haft tidligere på bloggen – Løgnedetektorer og screening for sygdom
Jeg har lavet tekster til NCUM, Nationalt Center for Udvikling af Matematikundervisning, om epidemimatematik, og herunder én om test. Den får I næsten ufordøjet her – husk, at den ikke er lagt ud af NCUM endnu. Det kommer på sitet Matematikdidaktik.dk
Test
Under en epidemi er det vigtigt at kunne identificere de smittede, så de kan undgå at smitte videre. Især når man kan smitte andre uden selv at have symptomer, er det vigtigt at kunne teste for sygdommen. Der testes også i mange andre tilfælde: For at give den rette diagnose og dermed den rette behandling, for at finde sygdom tidligt, så behandlingsmulighederne er bedre etc. Den matematik, der beskriver tests, er den samme uanset formålet med testen.
Om en test for en sygdom er god, afhænger af, om den finder de syge, men også af, om den ”finder de raske”, altså ikke erklærer folk syge, som ikke er det. Ekstremet er, at alle erklæres syge. Så har testen fundet alle syge, men det er naturligvis ikke en god test.
Skematisk er der for den enkelte disse muligheder:
| Testresultatet er |
Personen er |
| Syg |
Rask |
| Testen viser |
Syg |
Rigtigt |
Forkert |
| Rask |
Forkert |
Rigtigt |
Der er to tal, der karakteriserer en test:
- Hvor stor en andel af de syge får testsvaret ”syg” (man siger, de tester positivt, hvilket kan give megen forvirring, eftersom det sjældent er positivt at være syg). Den andel kaldes sensitiviteten.
- Hvor stor en andel af de raske får testsvaret ”rask” (tester negativt). Den andel kaldes
De to tal er sjældent lige store. Begge skal helst være ret høje: Hvis sensitiviteten er lav, vil mange syge ikke blive opdaget (det er de falske negative), de kommer så ikke rettidigt i behandling og de kan måske smitte andre, når de efter testen tror, de er raske. Hvis specificiteten er lav, vil mange raske teste positivt (falske positive) og komme i behandling – det koster, og kan måske have bivirkninger. De to tal er indbyrdes afhængige: Man kan flytte grænsen for, hvornår testen betragtes som positiv – hvor meget antistof, hvor stor mængde virus,… Det flytter på både specificitet og sensitivitet.
Et andet spørgsmål kan være: Hvor stor en andel af dem, der tester positivt, er faktisk syge? Det afhænger af, hvor stor en andel af de testede, der faktisk er syge – prævalensen. Så det kan man ikke regne ud alene på basis af testens egenskaber (specificitet og sensitivitet).

Winston Centre and Luna9
Eksempel med udgangspunkt i antal:
Om en test har vi fået oplyst, at der er 100 syge og 900 raske. Og at testen viser Syg for 90 af de syge. Syg for 10 af de raske. Rask for 20 af de syge og Rask for 880 af de raske.
Hvor stor er risikoen for, at en syg person tester rask? Hvad er omvendt chancen for, at en syg tester syg.
Hvor stor er risikoen for, at en rask person tester syg? Og hvad er chancen for, at en rask tester rask?
Bemærk, at disse oplysninger ikke er normalt resultat af en test. Man ved ikke, hvem der er syge – det er derfor, man tester. Man kan forestille sig, at man prøver en ny test af på personer, der er testet med en kendt og meget troværdig test. (Det er det, vi gør, når vi tester igen med PCR)
Eksempel med udgangspunkt i andele:
En test finder 80 % af de syge (har en sensitivitet på 80 %) dvs. ud af 100 syge, vil 80 teste positivt.
Den finder 90 % af de raske (har en specificitet på 90%) dvs. ud af 100 raske, vil 90 teste negativt.
Hvis testen bruges på hele befolkningen og ca. 1% har sygdommen sker følgende for 1000 personer:
Der er 10 syge. Af dem tester 8 positivt.
Der er 990 raske. Af dem tester 99 personer positivt.
I alt er 107 testet positivt, men kun de 8 er syge. Det er 8/107, omkring 7%. Det er den positivt prædiktive værdi. Det er den, der er interessant for den enkelte: Hvis man er testet positiv, er der stadig 93% chance for, at man er rask
Hvordan med dem, der tester negativt? Dem er der 2+891=893 af. Og det er 2/893= 0,2%, der faktisk er syge. Den negativt prædiktive værdi er 99,8% (så man er ganske sikker på at være rask, hvis man er testet negativ).
Nu bruges samme test på 100 personer, der allerede har et eller flere symptomer. Man ved, at prævalensen da er 20%
Der er 20 syge. Af dem tester 16 positivt.
Der er 80 raske. Af dem tester 72 negativt.
I alt er 16+8=24 testet positivt og de 16 er syge. Den positivt prædiktive værdi er da 16/24, omkring 67%. Det er nu den positivt prædiktive værdi.
I alt er 4+72=76 testet negativt og de 72 er raske. Den negativt prædiktive værdi er 72/76, omkring 95%
Spørgsmål: Hvordan ændrer de prædiktive værdier sig generelt, hvis man kun tester den del af befolkningen, der har symptomer? (Prævalensen er større)
Mere generelt og med sandsynligheder:
| Falsk Negative FN |
Sandt Positive SP |
Syge |
| Sandt Negative SN |
Falsk Positive FP |
Raske |
| Testet Negativt |
Testet Positivt |
Alle |
I tabellen er resultatet af en test. Som udgangspunkt kender vi den nederste række, men egenskaber ved testen og en kendt prævalens kan give de andre celler.
Tabellen kan betragtes som andele af dem, der er testet eller som de faktiske antal. Har man de faktiske antal kan man få andele ved at dividere værdierne i alle celler med tallet ”Alle”. Omvendt: Har man andele og kender det samlede antal, kan alle andelene multipliceres med ”Alle”.
Opgave:
Nedenfor opstiller vi formler for de begreber, der blev beskrevet tidligere. Forsøg i hver tilfælde at argumentere for formlens rigtighed. Overvej, at det ikke afhænger af, om tabellen er andele eller faktiske antal.
Specificitet er  , andelen af de raske, som tester negativt, altså sandsynligheden for at testen viser, man er rask, givet man er rask, det er den betingede sandsynlighed P(negativ|rask).
, andelen af de raske, som tester negativt, altså sandsynligheden for at testen viser, man er rask, givet man er rask, det er den betingede sandsynlighed P(negativ|rask).
Sensitiviteten er  , andelen af syge, der tester positivt, igen en betinget sandsynlighed P(positiv|syg).
, andelen af syge, der tester positivt, igen en betinget sandsynlighed P(positiv|syg).
Specificitet og sensitivitet er egenskaber ved testen.
Prævalensen, andelen, der er syge, er  .
.
Den positivt prædiktive værdi er  , andelen af positivt testede, som rent faktisk er syge, sandsynligheden for at være syg, når testen viser, man er det, P(syg|positiv). Det afhænger ikke kun af testen, men også af prævalensen.
, andelen af positivt testede, som rent faktisk er syge, sandsynligheden for at være syg, når testen viser, man er det, P(syg|positiv). Det afhænger ikke kun af testen, men også af prævalensen.
Eller, man kan se på den negativt prædiktive værdi  , andelen af negativt testede, der rent faktisk er raske P(rask|negativ).
, andelen af negativt testede, der rent faktisk er raske P(rask|negativ).
Opgaver:
Udnyt Bayes’ formel til at finde sammenhænge mellem eksempelvis sandsynligheden for at være syg givet man tester positivt og sandsynligheden for at teste positivt, givet man er syg. Hvilke andre sandsynligheder indgår? Genfind prævalensen som sandsynligheden for, at en tilfældig person er syg.












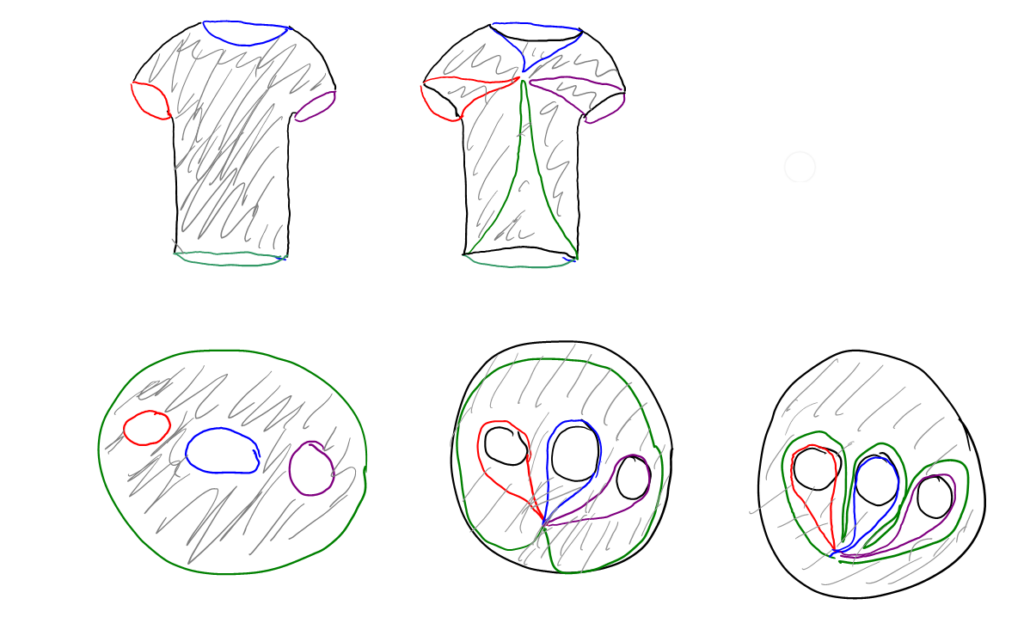
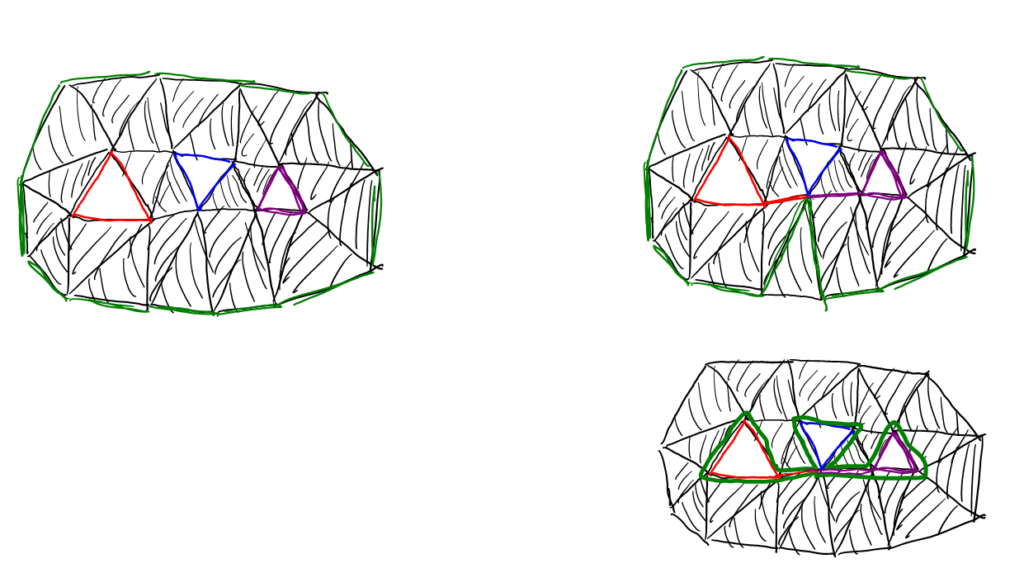
![\gamma : [0,1] \to X, \gamma(0)=\gamma(1)](https://s0.wp.com/latex.php?latex=%5Cgamma+%3A+%5B0%2C1%5D+%5Cto+X%2C+%5Cgamma%280%29%3D%5Cgamma%281%29&bg=ffffff&fg=000000&s=0 "\gamma : [0,1] \to X, \gamma(0)=\gamma(1)") Her er X badebolden eller torussen eller noget andet, man vil undersøge, og
Her er X badebolden eller torussen eller noget andet, man vil undersøge, og ![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=000000&s=0 "[0,1]") er intervallet fra 0 til 1.
er intervallet fra 0 til 1.  skal være kontinuert.
skal være kontinuert. hvis der er en fri homotopi:
hvis der er en fri homotopi:![H:[0,1]\times [0,1] \to X](https://s0.wp.com/latex.php?latex=H%3A%5B0%2C1%5D%5Ctimes+%5B0%2C1%5D+%5Cto+X&bg=ffffff&fg=000000&s=0 "H:[0,1]\times [0,1] \to X")
") så
så =\gamma(t)") ,
, =H(1,s)") for alle s, og
for alle s, og =\mu(1)") . H skal være kontinuert.
. H skal være kontinuert. 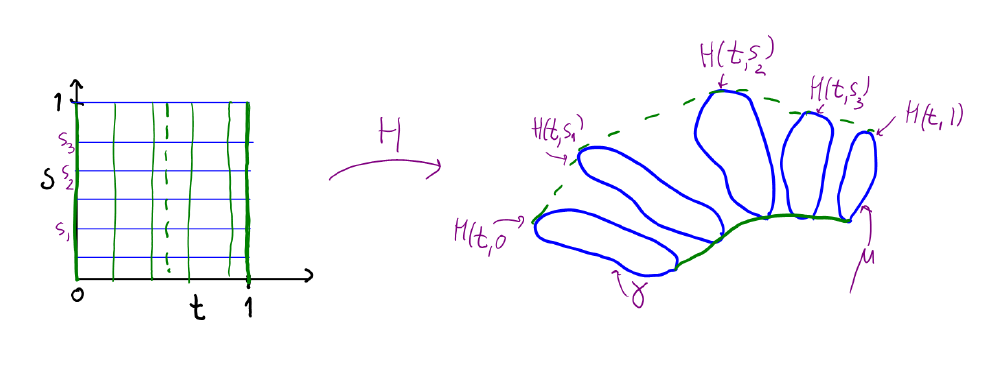
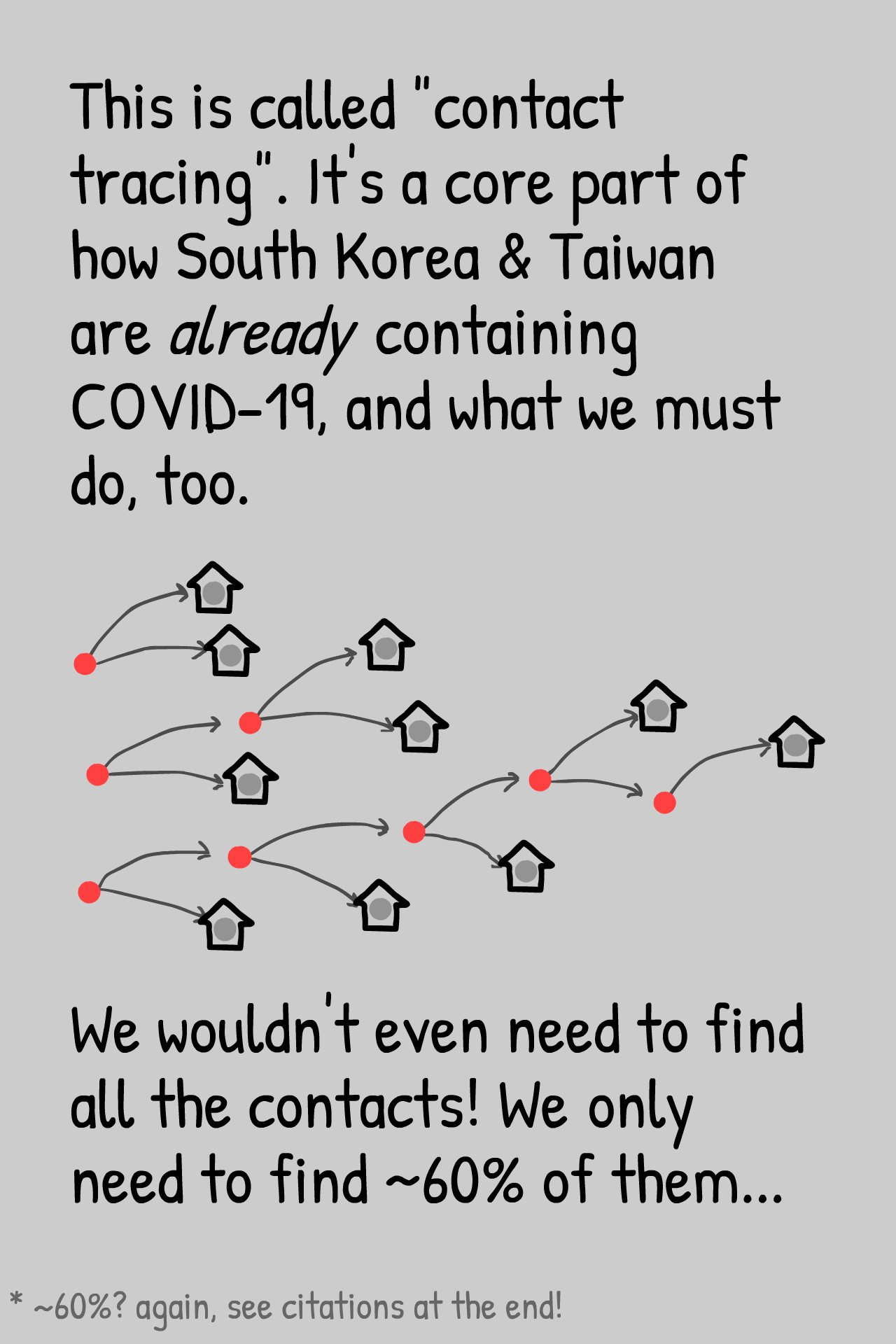
 .
. af befolkningen med en 100 % effektiv vaccine, før kontakttallet forventes at være under 1. MEN: Kontakttallet er 1,2 fordi vi lige nu overholder en lang række restriktioner og tak for det! Hvis vi nu ikke synes, det skal blive ved – selvom man vel godt kan blive ved med at vaske hænderne ordentligt – så er det et andet kontakttal, vi skal bruge. Hvad er det tal? Det kan man ikke svare helt sikkert på. Wikipedia citerer lige nu artikler for, at den grundlæggende reproduktionsrate,
af befolkningen med en 100 % effektiv vaccine, før kontakttallet forventes at være under 1. MEN: Kontakttallet er 1,2 fordi vi lige nu overholder en lang række restriktioner og tak for det! Hvis vi nu ikke synes, det skal blive ved – selvom man vel godt kan blive ved med at vaske hænderne ordentligt – så er det et andet kontakttal, vi skal bruge. Hvad er det tal? Det kan man ikke svare helt sikkert på. Wikipedia citerer lige nu artikler for, at den grundlæggende reproduktionsrate,  , er mellem 2 og 6. Kontakttallet er mindre end
, er mellem 2 og 6. Kontakttallet er mindre end  immune. Skal det give 2/3 (de 67%) kræver vi
immune. Skal det give 2/3 (de 67%) kræver vi  (man dividerer med 0,7) altså
(man dividerer med 0,7) altså  , godt 95%.
, godt 95%. godt 74%.
godt 74%.
 .
. hvor
hvor  er antal bit (her 12).
er antal bit (her 12).












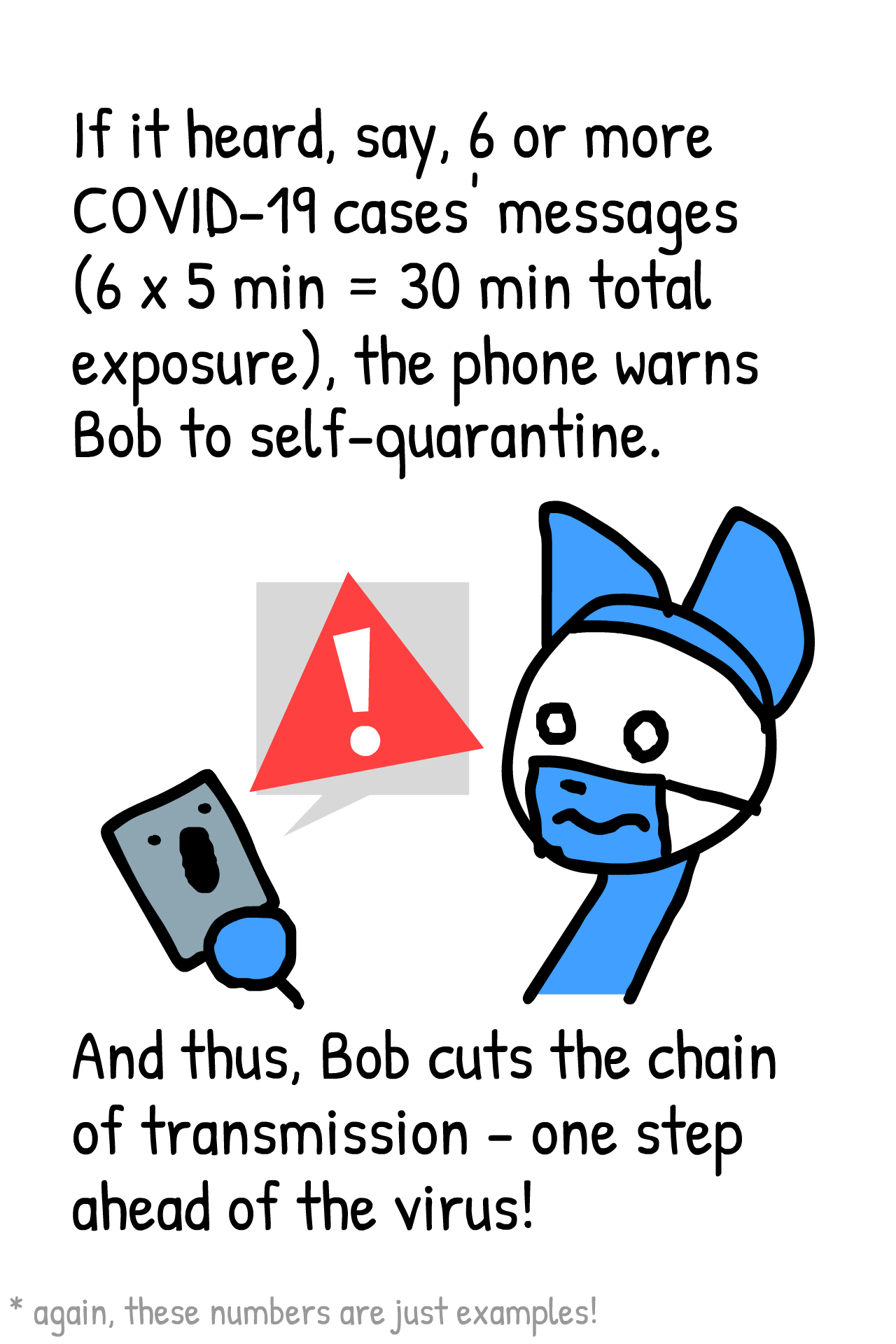



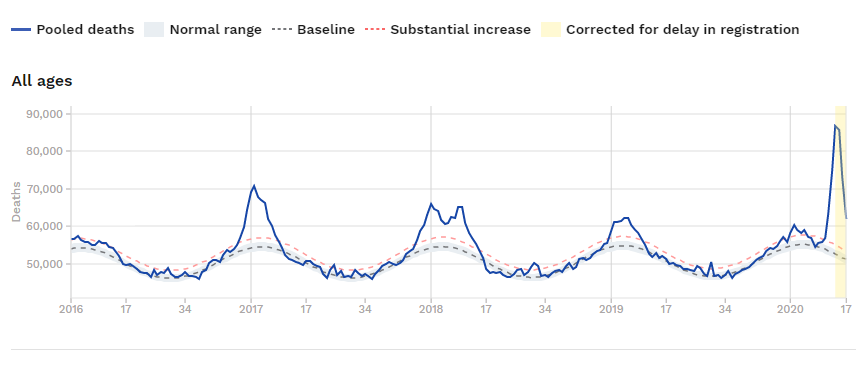
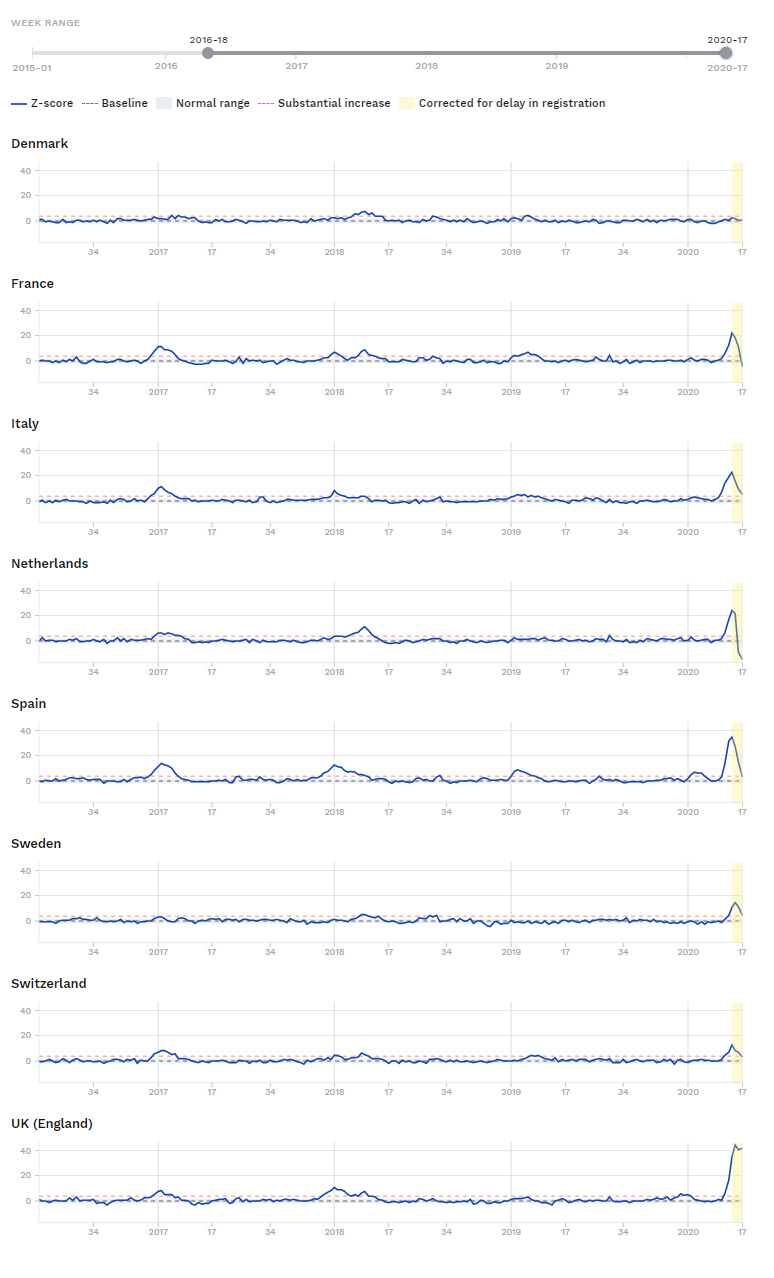
 , hvor den stiplede røde kurve ligger – så er man substantielt over.
, hvor den stiplede røde kurve ligger – så er man substantielt over.