I 2014 fandt en tysk statistiker, Thomas Royen, et bevis for en formodning fremsat i 1959. Royen skrev beviset ned og sendte det til Donald Richards, som er professor i statistik ved Pennsylvania State University. Og så bliver historien lidt mystisk: Ifølge Quanta Magazine havde Richards forsøgt at bevise formodningen i 30-40 år; han forstod, at Royens bevis var korrekt og alligevel blev den viden ikke spredt særlig effektivt. Der ser ud til at have været et hav af forkerte beviser i omløb, så måske er det druknet i det hav. Royen publicerede det i ArXiv, hvor vi allesammen lægger de næsten færdige versioner af artikler – nogenlunde samtidig med, vi sender dem til et tidsskrift. Royen valgte tidsskriftet The Far East Journal of Theoretical Statistics, et af de mange tidsskrifter med et tvivlsomt ry. Det burde nogen nok have frarådet. Men man kan da undre sig over, at det alligevel ikke blev spredt af eksempelvis Richards. Da to polske statistikere skrev en artikel, som er en gennemgang af beviset i detaljer, fik flere øje på resultatet og det er præsenteret ved Bourbakiseminar i januar i år – samme dag som Helfgott talte om grafisomorfiproblemet. Nå, men hele “human interest” historien kan I finde mange steder. Lad os se, hvad det er for en formodning.
Slår man med en terning, er sandsynligheden for en sekser 

=P(A)P(B)")
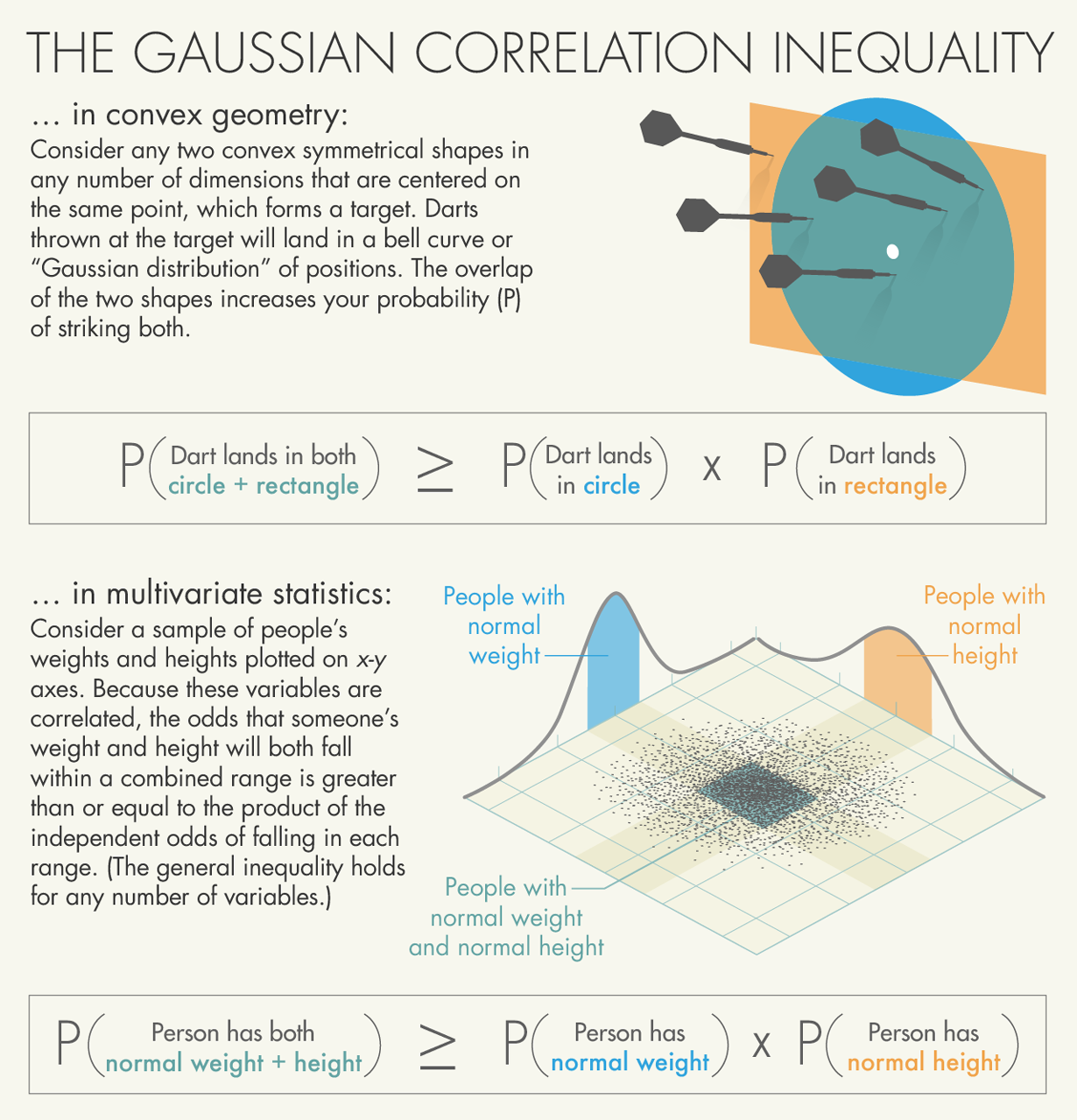
Den Gaussiske korrelationsulighed siger følgende: Hvis A og B er konvekse delmængder (hvis p og q er i A, så er linjestykket mellem p og q i A) af 
\geq P(A)P(B)")
En mere langhåret version siger: \geq \mu_n(A)\mu_n(B)")

Den oprindelige version fra 1959 handler ikke umiddelbart om konvekse delmængder af planen, men om rektangler. Vi måler en række forskellige størrelser, eksempelvis højde, vægt og mellemrum mellem fortænderne. Vi ved tilfældigvis, at alle disse størrelser hver for sig er normalfordelt med middelværdi hhv. H, V og F. Vi ved nu, at 95% af alle målinger af højder falder i intervallet [H-h, H+h], 95% af alle vægtmålinger i intervallet [V-v, V+v] og mellemrum mellem fortænderne i intervallet [F-f, F+f].
Den Gaussiske korrelationsulighed siger, sandsynligheden for, at et datapunkt (x,y) (højde, vægt for en konkret person) ligger i rektanglet [H-h,H+h]x[V-v,V+v] er mindst ^2")
^3")
I Quanta Magazine er en fin illustration, som jeg naturligvis ikke kopierer ind her – det må man ikke… Men kig selv på den. Nedenfor er en version fra Wikipedia – tænk på højde og vægt ovenfor. Højden er den røde kurve, vægten den blå. Det samlede kan man tænke sig som en klokkeformet graf over x-y-planen, som figuren længere nede viser. Den grønne ellipse illustrerer 
{kind=link}

