Ved statsministerens pressemøde inden påske, hvor en gradvis “åbning” af Danmark blev lanceret, fortalte Kåre Mølbak fra Statens Serum Institut, at de har fremskrevet mulige scenarier ved at bruge matematiske modeller. I TV2News’ løbende undertekster stod “matematiske modeller” – altså med anførselstegn. Man kan se, at det er uvant, at der udtrykkeligt tales om matematiske modeller til et pressemøde…. selvom der er matematiske modeller bag valg af finansiering af stort set hvert eneste politiske udspil.
I Nature beder Julia Gog, britisk epidemiolog, om at slippe for, at for mange overfylder epidemiologernes inboxe og diverse preprintarkiver med halvbagte beregninger – hvis man virkelig vil hjælpe og har evnerne, vil det være godt at fortælle, hvad modellerne går ud på. Se det er et kampråb jeg kan forstå. Og reagere på.
Først lidt generelt om matematiske modeller: Det er modeller – ikke virkeligheden. Når man laver en matematisk model vælger man at se bort fra noget af virkeligheden. Det gælder om
- Modellen skal være simpel nok til, at man kan håndtere matematikken i den.
- Resultaterne af at “regne” på matematiksiden skal være væsentlige og relevante for den virkelige problemstilling.
- Output fra modellen skal kunne fortolkes, give mening og være nogenlunde retvisende for den virkelighed, der skal beskrives og påvirkes.
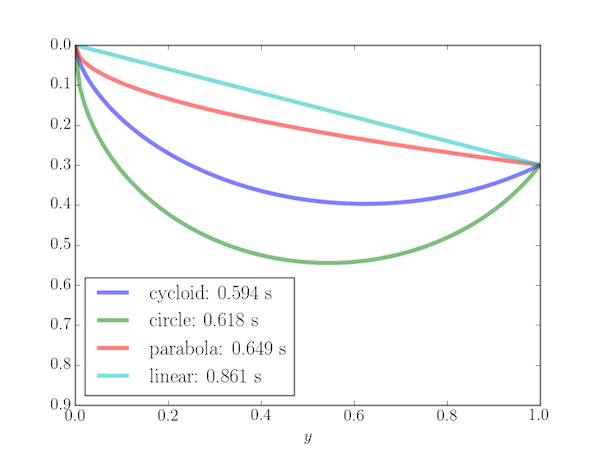
Hvor god modellen er afhænger i høj grad af, hvor godt man forstår den virkelig problemstiling, hvor meget og hvor præcist data, man har, hvor hurtigt, man kan få fat i data etc. Derfor vil output fra modeller ofte komme med flere mulige scenarier vægtet med forskellig sandsynlighed. Her er eksempelvis ekspertgruppens prognose for indlæggelser på intensiv, hvis vi havde opretholdt restriktionerne fra før påske, men slækket på “social afstand”, som det kaldes.. Det går, som man kan se, ganske overordentlig meget galt med en ikke så lille sandsynlighed.
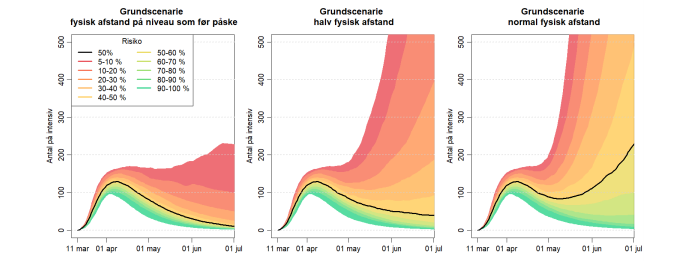
Hvor ved ekspertgruppen så det fra – hvordan laver de beregningerne? Hvad er modellen? Det får I ikke hele historien om – jeg er ikke epidemiolog – kan knap stave til det – men jeg kan løfte lidt af sløret – jeg har læst mig til noget og vidste lidt i forvejen.
Epidemimodeller. SIR og SEIR.
En meget simpel model for epidemier er SIR-modellen. Det er en kompartmentmodel hvor befolkningen er delt i “kasser” og flytter rundt mellem disse kasser. Her står S for Susceptible (de raske, der kan smittes), I for Infected (dem, der smitter), R for recovered (dem, der ikke smitter mere eller kan smittes). Man ser på en samlet population, som så enten er smitbare (S), smittede (I) eller (R):har været smittet, nu ikke smitbare og heller ikke smitter – herunder er også dem, der er døde.
S+I+R er konstant. Det er jo den samlede befolkning. Så Recovered inkluderer dem, der er døde.
Som tiden går flytter personer mellem S, I og R. Det er altså funktioner af tiden S(t), I(t) og R(t).
HVordan flytter de rundt? Lad mig først udvide modellen til en SEIR, hvor E er Exposed – de er smittet, men smitter ikke endnu.
Hvor mange flytter fra S til E? Tiden kan her sættes til at svare til dage. Så hvordan udvikler S,E, R sig, hvis vi kender S(t), E(t), I(t), R(t) til et tidspunkt? Det afhænger af, hvor smittefarlig sygdommen er og hvor mange møder, der er mellem smittede og raske. Det plejer vi at modellere som en sædvanlig differentialligning (“sædvanlig” er et fagudtryk – “ordinary” er den engelske pendant – S,E,I,R er funktioner af t, tiden og ikke andet – vi har nemlig også funktioner af flere variable):
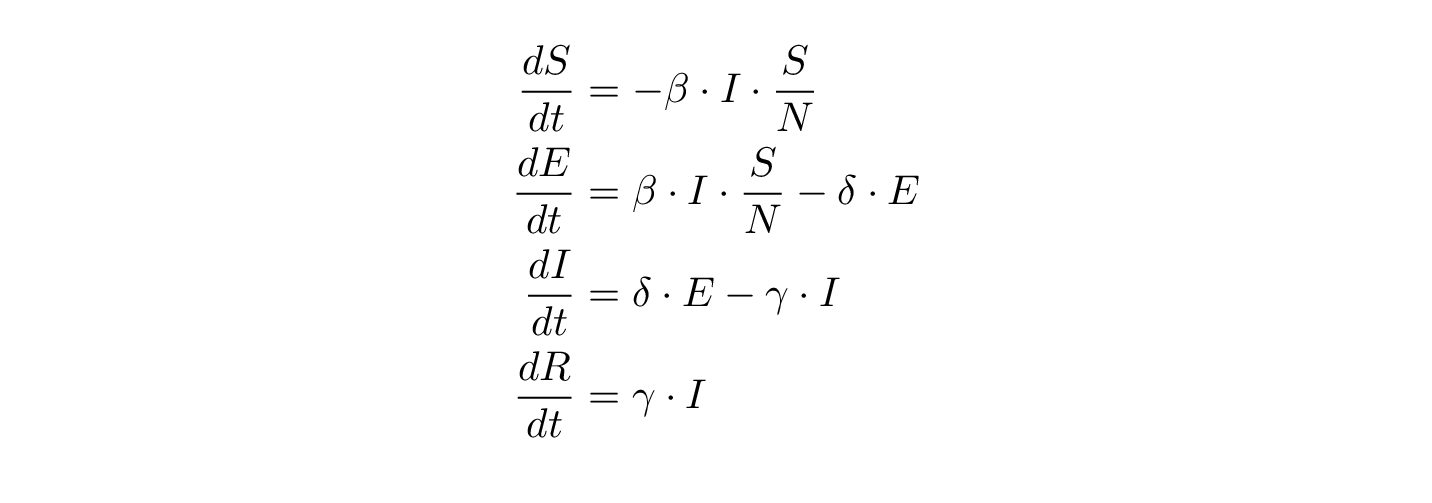
Lad mig starte nedefra: 


Man kan allerede med denne model se, at det kan hjælpe på epidemiens udvikling at sætte syge i karantæne. Så bliver I(t) mindre og der smittes ikke så mange.
Det er imidlertid en meget, meget simpel model. Hvis man skal lave de grafer, ekspertgruppen har lavet, skal man for eksempel vide, hvilken del at befolkningen, der bliver smittet – der er stor forskel på, hvor syg man bliver og dermed, om man skal på intensiv afdeling.
Det kan man reparere på ved at lave flere kompartments: Opdeling i aldersgrupper, som så er underopdelt i S, E, I, R, altså eksempelvis raske 0-5-årige. Det giver en finere model, hvor man kan tage hensyn til, hvilke dele af befolkningen, der mødes og dermed om de smittede 50-55-årige smitter de 0-5-årige.
I England lavede man et “citizens science” projekt hvor 36.000 personer rapporterede om deres kontaktmønstre – hvem mødes de med og hvor (arbejde, hjemme, skole,…) Der var også automatisk indrapportering via GPS og telefoner. Ud af det kom eksempelvis kontaktmatricen nedenfor:
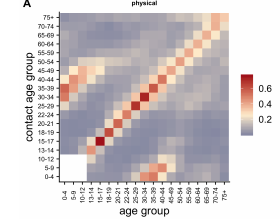
De hvide felter er manglende data – børn under 12 rapporterede ikke, eller der var ikke nok med.
Det giver en indikation af, at vi mødes med jævnaldrende og børn mødes med deres forældre.
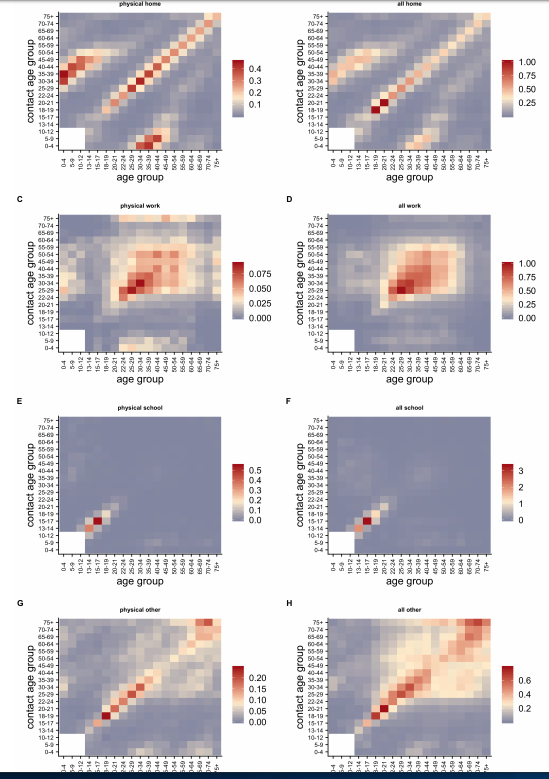
Hjælper det, at vi holder os hjemme? Det afhænger af, hvor vi mødes med hinanden og det har projektet i England også undersøgt. Søjlen til venstre er fysisk kontakt, til højre al kontakt – defineret passende – måske skal man tale med folk eller passere tæt på dem.
Det giver tydeligvis input til, hvad man får ud af at holde os hjemme fra arbejde. Desuden er fysisk kontakt minimeret ved “social distancing”. Man kan omvendt også se noget om, hvad det betyder at lade børn komme i skole.
Men, men: Det er en model for et land – Storbritannien. I Danmark er vores kontakter formentlig anderledes – i Storbritannien har de eksempelvis kostskoler, universitetsstuderende bor på universiteterne. De har færre vuggestuepladser og mange andre forskelle. Men uanset hvad: Man skal bruge viden om, hvordan og hvor vi mødes. Måske giver vi flere knus? Eller færre? (Det gør vi i hvert fald nu…)
Det er altså¨ganske indviklede modeller, men overordnet set drejer det sig om compartmentmodeller.
Den simple version, hvor befolkningen ikke underdeles efter alder, kan man læse mere om på dansk her. hvor kompartmentmodellen er udvidet med et Q for karantæne. Der er også mulighed for at “lege” med modellen. Men husk hele tiden, at det, der bruges af eksperterne, er mere kompliceret og i øvrigt skifter – man lærer mere om epidemien undervejs, kender antal syge bedre,…
Lige nu er AAU og DTU igang med en såkaldt agentbaseret model, hvor man simulerer enkeltindivider. På matematik her er det Torben Tvedebrink, Mikkel Meyer Andersen og Janus Valberg-Madsen, der er med i det projekt. Det kan være, de fortæller mere om det, men vi har jo egentlig ganske travlt med at holde universiteterne i luften med online undervisning.
 (udtales “r seks” og ikke “r i sjette”) At vi så ikke lige kan tegne det ind i et koordinatsystem er en anden sag. Man kan sagtens regne med 6 koordinater uden at tegne. I det følgende tænker jeg ind imellem på sådan et punkt som en vektor – fra Origo til (1,-3,7,0,534,14) – og ind imellem som et punkt.
(udtales “r seks” og ikke “r i sjette”) At vi så ikke lige kan tegne det ind i et koordinatsystem er en anden sag. Man kan sagtens regne med 6 koordinater uden at tegne. I det følgende tænker jeg ind imellem på sådan et punkt som en vektor – fra Origo til (1,-3,7,0,534,14) – og ind imellem som et punkt.") og b=
og b= ")
")
") (her er k et reelt tal.)
(her er k et reelt tal.) – gang koordinater sammen parvis og læg resultaterne sammen.
– gang koordinater sammen parvis og læg resultaterne sammen.
\cdot (a-b)}}")
=\frac{\mathbf{a\cdot b}}{|\mathbf{a}||\mathbf{b}|}")
 Med centrum i Origo og radius 1 får vi
Med centrum i Origo og radius 1 får vi , de punkter i
, de punkter i  og ikke
og ikke  ? Fordi sådan en kugleflade har en dimension mindre – ligesom man kan have planer i
? Fordi sådan en kugleflade har en dimension mindre – ligesom man kan have planer i  . Den historie må også vente… Kuglefladen i
. Den historie må også vente… Kuglefladen i  og
og  er en cirkel.
er en cirkel. er en kasse, et hyperrektangel om man vil.
er en kasse, et hyperrektangel om man vil. , en hyperkube. Altså punkter
, en hyperkube. Altså punkter ") , hvor alle koordinater ligger mellem 0 og 1. Ydersiden af sådan en kube er der, hvor mindst en af koordinaterne er enten 0 eller 1. En sædvanlig kube har 6 sideflader:
, hvor alle koordinater ligger mellem 0 og 1. Ydersiden af sådan en kube er der, hvor mindst en af koordinaterne er enten 0 eller 1. En sædvanlig kube har 6 sideflader: ")
")
")
")
")
") .
.")
") ,
, ")
")
")
")
")
") . De hænger sammen – ligesom sidefladerne på en sædvanlig kube. Man kan selvfølgelig ikke se det i vores sædvanlige dimension, men man kan lave en film, hvor man ser projektionen af en roterende hyperkube:
. De hænger sammen – ligesom sidefladerne på en sædvanlig kube. Man kan selvfølgelig ikke se det i vores sædvanlige dimension, men man kan lave en film, hvor man ser projektionen af en roterende hyperkube:

 er en funktion
er en funktion  ,
, =(r_1(t),r_2(t),\ldots,r_n(t)") , funktionen tager én koordinat ind og giver n koordinater ud. Man kan også sige, at den består af n koordinatfunktioner.
, funktionen tager én koordinat ind og giver n koordinater ud. Man kan også sige, at den består af n koordinatfunktioner. findes et
findes et  , så
, så  garanterer, at
garanterer, at -r(t_0)|<\varepsilon")
,r_2(t))") startende med t=0 sluttende med t=1. Det er en kontinuert kurve (ellers kan alt lade sig gøre i det computerspil 🙂 ).
startende med t=0 sluttende med t=1. Det er en kontinuert kurve (ellers kan alt lade sig gøre i det computerspil 🙂 ).,r_2(0)|<1") , fordi jeg begynder indenfor cirklen. Og
, fordi jeg begynder indenfor cirklen. Og ,r_2(1)|>1") , fordi jeg ender udenfor. Nu påstår jeg, at der er et tidspunkt
, fordi jeg ender udenfor. Nu påstår jeg, at der er et tidspunkt  , hvor
, hvor |=1") . Hvorfor? Jo, den sammensatte funktion
. Hvorfor? Jo, den sammensatte funktion = |r(t)|") er kontinuert og g(0)<1, g(1)>1. Så siger mellemværdisætningen, at der findes
er kontinuert og g(0)<1, g(1)>1. Så siger mellemværdisætningen, at der findes }") , andelen af de raske, som tester negativt, altså sandsynligheden for at testen viser, man er rask, givet man er rask, P(testrask|rask).
, andelen af de raske, som tester negativt, altså sandsynligheden for at testen viser, man er rask, givet man er rask, P(testrask|rask).}") , andelen af syge, der tester positivt P(testsyg|syg).
, andelen af syge, der tester positivt P(testsyg|syg).}") , andelen af positivt testede, som rent faktisk er syge, sandsynligheden for at være syg, når testen viser, man er det, P(syg|testsyg).
, andelen af positivt testede, som rent faktisk er syge, sandsynligheden for at være syg, når testen viser, man er det, P(syg|testsyg).}") , andelen af negativt testede, der rent faktisk er raske P(rask|testrask).
, andelen af negativt testede, der rent faktisk er raske P(rask|testrask).


 Billede fra Wikipedia – cell junctions.
Billede fra Wikipedia – cell junctions.") . Cellekernerne på de to forskellige cylindere har altså samme
. Cellekernerne på de to forskellige cylindere har altså samme ") , men forskellig
, men forskellig 

 på den anden. Med samme højde og radius R er det h på den ene led og
på den anden. Med samme højde og radius R er det h på den ene led og  på den anden. Og så ændrer Voronoicellerne sig kvalitativt. På billederne nedenfor, som
på den anden. Og så ændrer Voronoicellerne sig kvalitativt. På billederne nedenfor, som 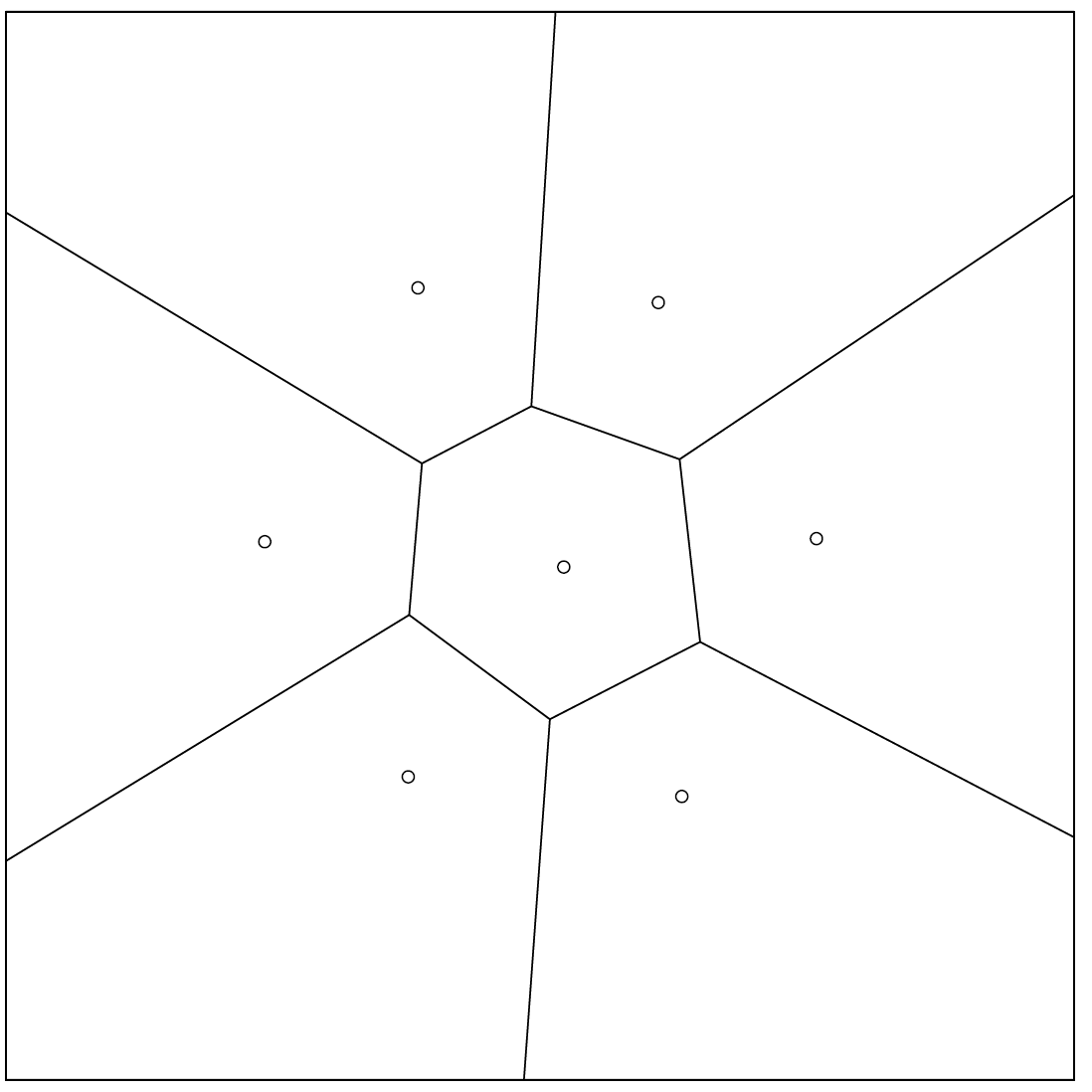


 . (I familie med Sierpinskis tæppe, Mengers svamp,…)
. (I familie med Sierpinskis tæppe, Mengers svamp,…)  Hun har mere om det
Hun har mere om det 

 og centrum i
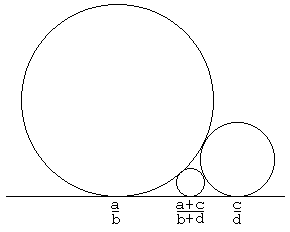
og centrum i ") . Bed nu en anden om at gøre det samme – med nyt valg af p og q. De to cirkler vil tangere x-aksen og enten tangere hinanden eller ikke have noget til fælles. Bliv ved og der opstår et fint mønster af cirkler. De kaldes Ford-cirkler, fordi de blev beskrevet i en
. Bed nu en anden om at gøre det samme – med nyt valg af p og q. De to cirkler vil tangere x-aksen og enten tangere hinanden eller ikke have noget til fælles. Bliv ved og der opstår et fint mønster af cirkler. De kaldes Ford-cirkler, fordi de blev beskrevet i en  , så
, så  og dermed er x-koordinaten for centrum mellem 0 og 1. Tallet i cirklen er x-koordinaten for centrum (forkortet, så det svarer til p/q). Farven indikerer nævneren p.
og dermed er x-koordinaten for centrum mellem 0 og 1. Tallet i cirklen er x-koordinaten for centrum (forkortet, så det svarer til p/q). Farven indikerer nævneren p.
") så afstand mellem centrene opfylder
så afstand mellem centrene opfylder^2+(\frac{1}{2q^2}-\frac{1}{2s^2})^2")

 . Hvis de to cirkler skærer hinanden er
. Hvis de to cirkler skærer hinanden er  . Tangerer de, er
. Tangerer de, er  .
.^2+(\frac{1}{2q^2}-\frac{1}{2s^2})^2-(\frac{1}{2q^2}+\frac{1}{2s^2})^2") =
=^2- 4(\frac{1}{2q^22s^2})") =
=^2- (\frac{1}{q^2s^2})") =
=^2-1}{(qs)^2}")
^2 - 1<0") og altså
og altså ^2 <1")






 er uforkortelige brøker mellem 0 og 1 med nævner højst n. Rækkefølgen er efter størrelse. De elementer, der tilføjes til
er uforkortelige brøker mellem 0 og 1 med nævner højst n. Rækkefølgen er efter størrelse. De elementer, der tilføjes til  er medianten af naboerne:
er medianten af naboerne: tilføjes
tilføjes  . Naboerne er
. Naboerne er  . Medianten er dårlig brøkregning, Fareyplus:
. Medianten er dårlig brøkregning, Fareyplus:
 ligger medianten imellem dem
ligger medianten imellem dem  . Man viser det første ulighedstegn som følger:
. Man viser det første ulighedstegn som følger: 

a<(a+c)b \Leftrightarrow da<cb") og det følger af
og det følger af  .
. tilføjes i skridtet fra
tilføjes i skridtet fra  er højst n+1.
er højst n+1. er naboer. Antag
er naboer. Antag  og $\frac{q}{p}$ er uforkortelig. Så er p>k, da medianten ikke er i
og $\frac{q}{p}$ er uforkortelig. Så er p>k, da medianten ikke er i  . Altså er r=1.
. Altså er r=1. til
til  .
. og tilføjer medianter.
og tilføjer medianter.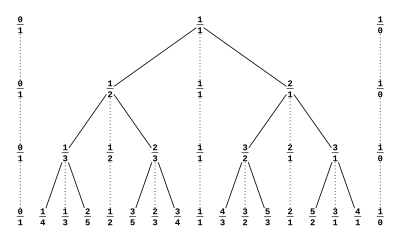
 er barn og forælder eller forælder og barn i træet (forbundet med en kant opad eller nedad fra
er barn og forælder eller forælder og barn i træet (forbundet med en kant opad eller nedad fra  til $latex \frac{c}{d}$, så er
til $latex \frac{c}{d}$, så er  . Bevis: Induktion. Det er ok for 0/1 og 1/1. Hvis ok for
. Bevis: Induktion. Det er ok for 0/1 og 1/1. Hvis ok for  eller opad
eller opad  .
.-a(b+d)=bc-ad=1") pr antagelse. Og tilsvarende for den anden side. (Lav selv et særargument for medianterne med hhv. 0/1 og 1/1.) En konsekvens er, at afstanden er
pr antagelse. Og tilsvarende for den anden side. (Lav selv et særargument for medianterne med hhv. 0/1 og 1/1.) En konsekvens er, at afstanden er  .
. . Omskriv de to uligheder til
. Omskriv de to uligheder til og
og  . Det er hele tal, så vi kan skrive
. Det er hele tal, så vi kan skrive  begge steder.
begge steder.(c+d)+(cq-dp)\geq c+d+a+b\geq p+q+1") (Det sidste følger af, at den ene brøk er fra niveau p+q)
(Det sidste følger af, at den ene brøk er fra niveau p+q)







 , hvor k er et naturligt tal. Det beviste Euler. Det er et eksempel på en reciprocitetslov – en egenskab ved primtallene udtrykkes ved division med rest . Her er det division med 4, som skal give rest 1. Vi skriver
, hvor k er et naturligt tal. Det beviste Euler. Det er et eksempel på en reciprocitetslov – en egenskab ved primtallene udtrykkes ved division med rest . Her er det division med 4, som skal give rest 1. Vi skriver 
 kaldes et Gaussisk heltal, hvis
kaldes et Gaussisk heltal, hvis  er hele tal. Hvis
er hele tal. Hvis  , så er
, så er (m-in)=p") ( husk,
( husk,  og så er resten givet ved at gange ind i paranteser) og omvendt. Et primtal p er et produkt af to Gausisske heltal hvis og kun hvis det er en sum af to kvadrattal.
og så er resten givet ved at gange ind i paranteser) og omvendt. Et primtal p er et produkt af to Gausisske heltal hvis og kun hvis det er en sum af to kvadrattal.  , hvor c og d er hele tal. Ganger, dividerer, adderer eller subtraherer man to Gaussiske rationale tal med hinanden, er resultatet rationalt. De Gaussiske rationale tal udgør derfor ikke bare en delmængde
, hvor c og d er hele tal. Ganger, dividerer, adderer eller subtraherer man to Gaussiske rationale tal med hinanden, er resultatet rationalt. De Gaussiske rationale tal udgør derfor ikke bare en delmængde ") af de komplekse tal, men et legeme. Man kan se det som en udvidelse af de rationale tal – man tilføjer
af de komplekse tal, men et legeme. Man kan se det som en udvidelse af de rationale tal – man tilføjer  og reglen
og reglen \to \mathbb{Q}(i)") , som er lineære: f((a+bi)+(c+di))=f(a+bi)+f(c+di) og bevarer produktstrukturen f((a+bi)(c+di))=f(a+bi)f(c+di) og desuden opfylder f(a+0i) = a+0i. Der er kun to afbildninger: Identitetsafbildningen f(a+bi)=a+bi og g(a+bi)=a-bi.
, som er lineære: f((a+bi)+(c+di))=f(a+bi)+f(c+di) og bevarer produktstrukturen f((a+bi)(c+di))=f(a+bi)f(c+di) og desuden opfylder f(a+0i) = a+0i. Der er kun to afbildninger: Identitetsafbildningen f(a+bi)=a+bi og g(a+bi)=a-bi. .
. og dermed kvadratrødder af alle negative rationale kvadrattal. Vi ved, at alle andengradspolynomier
og dermed kvadratrødder af alle negative rationale kvadrattal. Vi ved, at alle andengradspolynomier  med rationale a,b,c, har to rødder (mere præcist, kan skrives
med rationale a,b,c, har to rødder (mere præcist, kan skrives (x-r_2)") med
med ") og en formel for disse rødder kan skrives blot med brug af kvadratrodssymbolet.
og en formel for disse rødder kan skrives blot med brug af kvadratrodssymbolet. har rødder, som kan opskrives ved brug af kvadratrødder og kubikrødder. Tilsvarende for 4.gradspolynomier, når man tilføjer fjerde rødder. Men for femtegradspolynomier går det galt. Det viste Abel og Galois. Det er altså ikke nok at kunne løse ligninger
har rødder, som kan opskrives ved brug af kvadratrødder og kubikrødder. Tilsvarende for 4.gradspolynomier, når man tilføjer fjerde rødder. Men for femtegradspolynomier går det galt. Det viste Abel og Galois. Det er altså ikke nok at kunne løse ligninger  for at kunne løse alle femtegradspolynomieligninger. Det mere generelle spørgsmål er, om der er en sammenhæng mellem løsninger til et polynomium
for at kunne løse alle femtegradspolynomieligninger. Det mere generelle spørgsmål er, om der er en sammenhæng mellem løsninger til et polynomium ") og et andet
og et andet ") .
. , hvis
, hvis  og
og  , hvis
, hvis  . Funktionen
. Funktionen  kaldes en Frobeniusafbildning og er et element af Galoisgruppen. Frobeniusafbildningen er forbindelsen mellem “kan man skrive p som en sum af to kvadrattal” og “hvad er
kaldes en Frobeniusafbildning og er et element af Galoisgruppen. Frobeniusafbildningen er forbindelsen mellem “kan man skrive p som en sum af to kvadrattal” og “hvad er  “.
“. har rod 1, når man regner modulo 3, da
har rod 1, når man regner modulo 3, da  . Men 1 er ikke en rod modulo 5. Hvor meget information er der i, at kende antallet af rødder modulo primtal? Og hvad har det med Galoisgrupper at gøre?
. Men 1 er ikke en rod modulo 5. Hvor meget information er der i, at kende antallet af rødder modulo primtal? Og hvad har det med Galoisgrupper at gøre?