Lisbeth Fajstrup spurgte mig tidligere på året, om jeg kunne skrive et blogindlæg, som svarede på de to følgende spørgsmål: (1) hvorfor skal 

Kort introduktion til p-værdier
Helt generelt defineres
Sandsynligheden for at observere en teststørrelse der er ligeså eller mere ekstrem, end hvad der allerede er observeret, givet at nulhypotesen er sand.
For at illustrere, hvordan dette skal forståes, lad os tage et eksempel:
Lad os sige, at vi vil undersøge om befolkningen bakker op om Formel 1 ræs i København. Vores nul hypotese er at befolkningen hverken er for eller imod, altså at opbakningen er fifty-fifty. Alternativet er, at opbakningen er mindre eller større end 
Vi går ud i landet og spørger seks tilfældige personer. Det viser sig at alle seks personer støtter op om forslaget. Under nulhypotesen er sandsynligheden for at se seks observationer ‘imod‘ forslaget:
=\left(\frac{1}{2}\right)^{6} = \frac{1}{64},")
og da vi ikke er forudindtagede, så er seks individer ‘for‘ forslaget lige så ekstrem en observation. (Og der kan ikke være observationer, som er mere ekstreme.) Dette medfører en
 + \mathbb{P}\left(6\text{ personer for}\right) = 2\cdot\frac{1}{64} = \frac{1}{32} = 0{,}03125.")
Er dette nok til at forkaste nulhypotesen? Hvis vi skal spørge det hav af lærebøger der bruges i statistik undervisning, vil de sige, at nulhypotesen forkastes så snart
Den udregnede 
Hvis vi sætter en beslutningsgrænse (signifikansniveau) kan vi begå to typer af fejl:
- Type I: Nulhypotesen forkastes selvom den er sand.
- Type II: Nulhypotesen forkastes ikke selvom den er falsk.
Sætter vi beslutningsgrænsen i vores eksempel ovenfor til, at alle seks er ‘for‘ eller alle seks er ‘imod‘, før vi forkaster nulhypotesen, så er sandsynligheden for at begå en Type I fejl 
Sandsynligheden for at vi begår en Type II fejl vil afhænge af signifikansniveauet og den sande andel af populationen som er ‘imod‘ (eller ‘for‘) Formel 1 løb i København. Lad os se hvad der sker, når vi antager at sande andel af populationen som er ‘imod‘ er 

 = \left(\frac{1}{4}\right)^{6},")
og sandsynligheden for at se seks observationer ‘for‘ er:
 = \left(\frac{3}{4}\right)^{6}.")
Dette giver en sandsynlighed for at begå en Type II fejl på:
 = \mathbb{P}\left(6\text{ personer imod}\right) + \mathbb{P}\left(6\text{ personer for}\right) = 0{,}17822,")
hvor ")
Det vil sige, at hvis den sande andel af populationen som er ‘imod‘ er 
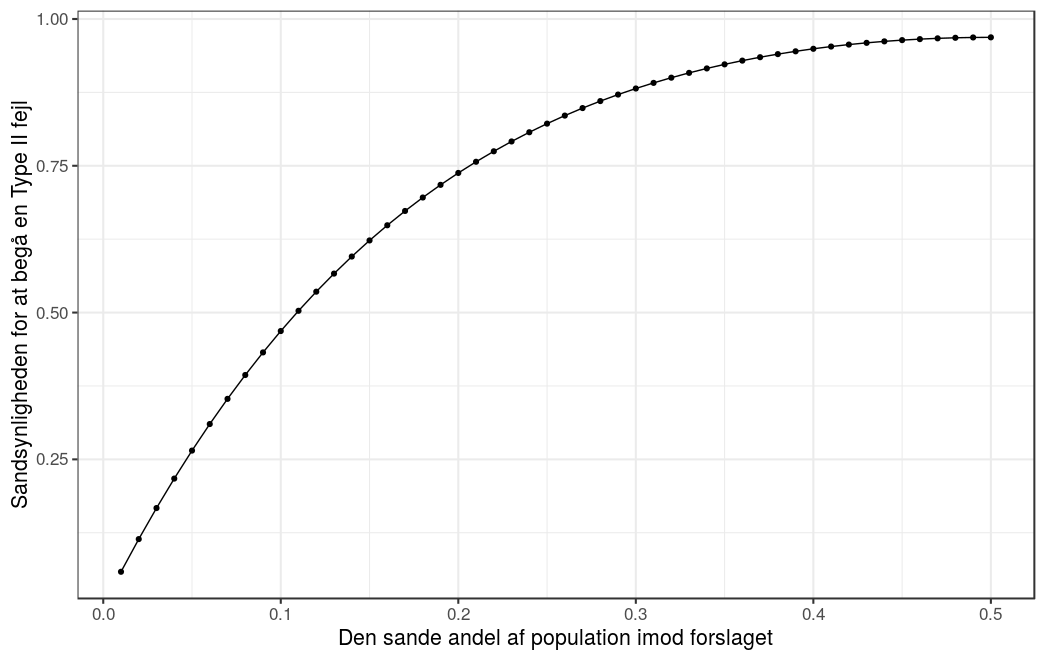
Grunden til den høje sandsynlighed for Type II fejl i denne sammenhæng er valget af signifikansniveau og, hovedsageligt, det lave antal af observationer. Dette betyder at når vi designer et studie, (planlægger, hvor mange og hvem, vi skal spørge/teste/…,) så prøver vi at finde en balance mellem tre størrelser: signifikansniveauet, styrken, og stikprøve størrelsen.
Hvorfor skal p-værdier være mindre end 5%, før de kaldes statistisk signifikante?
Ikke et specielt tilfredsstillende svar, men det er sandheden. Vi lærer vore elever og studerende det, fordi vi selv fik det at vide af vore undervisere. Dette svar, kombineret med at flere tidsskrifter i de seneste år har valgt at direkte afvise artikler der indeholder
Det simple svar er: fordi R. A. Fisher skrev det og hans ord lov. Fisher er en af de mest anerkendte statistikere, og bliver generelt betragtet som en af fædrene til moderne statistik. Et eksempel på Fishers brug af signifikansniveauet, kan ses i hans artikel fra 1926:
If one in twenty does not seem high enough odds, we may, if we prefer it, draw the line at one in fifty (the 2 per cent point), or one in a hundred (the 1 per cent point). Personally, the writer prefers to set a low standard of significance at the 5 per cent point, and ignore entirely all results which fail to reach this level. A scientific fact should be regarded as experimentally established only if a properly designed experiment rarely fails to give this level of significance.
Altså giver Fisher en følge af mulige signifikansniveauer efterfulgt af hans foretrukne niveau på 



Det heller ikke så vigtigt at signifikansniveauet lige præcist er 

Hvorfor lærer vi så stadig vore elever og studerende, at signifikansniveauet bør være
- Det leder, i de fleste tilfælde, til en god balance mellem andelen af Type I fejl, Type II fejl og størrelsen af stikprøven.
- Det gør det nemmere at sammenligne studier, hvis alle bruger det samme signifikansniveau og samme styrke.
- Det er nemmere at lære et stort antal elever en ‘kageopskrift’, end at få dem til at tage stilling til den andel af Type I og II fejl, de vil tillade i deres analyse.
Multiple testing problemet
Problemet opstår, når flere hypoteser testes på samme tid. Jo flere hypoteser der testes på samme tid, jo større er sandsynligheden for, at der opstår en fejl. Lad os i det følgende antage at andelen af acceptable Type I fejl er sat til
Lad os eksempelvis sige, at vi i stedet for at teste et nyfundent stof 



^{100}=0.994")
Sandsynligheden for mindst en Type I fejl, kaldes også ‘the familywise error rate‘ (FWER). Et oplagt spørgsmål er: hvordan kan vi sikrer at FWER er mindre end den acceptable andel af Type I fejl? Der har gennem årene været en del bud på løsninger til dette problem. Vi kaster et kort blik på den simpleste og mest anvendte procedure, Bonferroni korrektionen.
Lad 


hvor 




![\text{FWER} = \mathbb{P}\left(\bigcup\limits_{i=1}^{I}\left[p_i \leq \frac{\alpha}{I}\right]\right) \leq \sum_{i = 1}^{I} \mathbb{P}\left(p_i \leq \frac{\alpha}{I}\right) = I\frac{\alpha}{I} = \alpha,](https://s0.wp.com/latex.php?latex=%5Ctext%7BFWER%7D+%3D+%5Cmathbb%7BP%7D%5Cleft%28%5Cbigcup%5Climits_%7Bi%3D1%7D%5E%7BI%7D%5Cleft%5Bp_i+%5Cleq+%5Cfrac%7B%5Calpha%7D%7BI%7D%5Cright%5D%5Cright%29+%5Cleq+%5Csum_%7Bi+%3D+1%7D%5E%7BI%7D+%5Cmathbb%7BP%7D%5Cleft%28p_i+%5Cleq+%5Cfrac%7B%5Calpha%7D%7BI%7D%5Cright%29+%3D+I%5Cfrac%7B%5Calpha%7D%7BI%7D+%3D+%5Calpha%2C+&bg=ffffff&fg=000000&s=0 "\text{FWER} = \mathbb{P}\left(\bigcup\limits_{i=1}^{I}\left[p_i \leq \frac{\alpha}{I}\right]\right) \leq \sum_{i = 1}^{I} \mathbb{P}\left(p_i \leq \frac{\alpha}{I}\right) = I\frac{\alpha}{I} = \alpha,")
hvor første ulighed holder ved Booles ulighed, der siger at:
 \leq \sum_i \mathbb{P}\left(A_i\right).")
Bonferroni korrektionen er en særdeles konservativ metode, hvis der laves mange hypotese test eller
I de senere år, er dette blevet et problem ifm. ‘genome-wide association studies‘ (GWAS). Her testes forskellen i individers DNA baser (de byggesten vore kromosomer består af) for deres indflydelse på en sygdom eller et fænotypisk træk (så som hårfarve). Applikationer som denne, har ført til en række alternativer til Bonferroni korrektionen. Den mest anvendte her i blandt er ‘false discovery rate‘ (FDR), som blev formelt beskrevet af Yoav Benjamini og Yosef Hochberg i 1995, altså en forholdsvis ny metode i denne sammenhæng. Mere information kan findes på wikipedia siderne: ‘Multiple comparison problem‘, ‘Bonferroni correction‘, ‘False discovery rate‘, og ‘Genome-wide association study‘.