Dette indlæg er motiveret af https://fredhohman.com/card-shuffling/.
Opdateret 24/6-2018 10:20: Links til Numb3rs-bloggen tilføjet.
Spillekort skal blandes. En gængs måde at gøre det på, er at dele kortbunken i to mindre bunker af (ca.) samme størrelse og mikse de to bunker fra bund til top. På engelsk hedder det et riffle shuffle. (Jeg kender ikke det danske navn for denne måde at blande på.) Man kan overveje hvor mange gange dette skal gøres for bunken “er godt nok blandet” (for en passende definition af det). 7 gange er tilsyneladende nok (hvis man gør det rigtigt osv.). En matematisk model for denne måde at blande på er Gilbert-Shannon-Reeds modellen. Ovre på Numb3rs-bloggen er der mere om spillekort og matematik i dette indlæg. Bemærk at videoen (“7 gange er tilsyneladende nok”) er med Persi Diaconis som også omtales i Numb3rs-indlægget.
En mere simpel måde at blande på, er at tage det øverste kort og indsætte det et tilfældigt sted i bunken. Og sådan fortsætter man. Man kan nu stille sig selv det samme spørgsmål: hvor mange gange skal man gøre dette for at kortbunken er blandet “nok” (jf. ovenfor)?
Man kan vise (se fx 7 gange er tilsyneladende nok / https://fredhohman.com/card-shuffling/), at man i gennemsnit skal gentage en sådan simpel blanding 235 gange for at kortbunken er blandet “nok”. En del af svaret er, at bunken er blandet “nok” når bundkortet (det nederste kort i bunken inden man går i gang med at blande) har nået toppen af bunken og også selv er blevet blandet (dvs. flyttet til et tilfældigt sted i bunken).
I dette indlæg skal vi se, hvordan man kan opnå viden om eksempelvis sådanne processer ved at få computeren til at simulere mange, mange af sådanne blandinger og så registrere interessante egenskaber ved hver realiserede blanding. Denne fremgangsmåde kaldes for Monte Carlo-metoder og er et kraftfuldt værktøj indenfor statistikken. Man kan med en beskrivelse af den datagenererende process finde egenskaber for processen ved at få computeren til at realisere processen mange, mange gange.
Teoretiske resultater er ekstremt vigtige af mange årsager. Men det betyder ikke, at det er den eneste måde at opnå viden om processer på. Med Monte Carlo-metoden kan man dels kontrollere de teoretiske resultater, men ofte kan man faktisk opnå resultater som kan virke umulige at opnå teoretisk.
I dette tilfælde vil vi bruge Monte Carlo-metoden til at dels at finde det gennemsnitlige antal gange man skal blande før bunken er godt nok blandet. Det kan man også relativt let finde teoretisk (se ovenfor). Men man kunne også være interesseret i at finde fraktiler i fordelingen af antal blandinger. Så kan angive, at man i 95% af tilfældene skal blande mellem L og U gange før at bunken er blandet “nok”.
Den letteste måde at lave sådanne simulationer er på computeren med en random number generator (RNG), der kan generere tilfældige tal. Ofte må man nøjes med pseudorandom number generator (PRNG), men det er som regel også tilstrækkeligt. Og så skal man bruge et interface til denne PRNG således man kan få nogle tilfældige tal i beskrivelsen af processen. Ovre på Numb3rs-bloggen er der mere om tilfældige tal i dette indlæg.
Jeg vil her bruge R, der er et helt programmeringsmiljø (inkl. programmeringssprog) hovedsageligt anvendt til statistik, big data, maskinlæring, kunstig intelligens, dataanalyse m.fl. Det er et rigtigt godt vækrtøj at have i sin værktøjskasse. Rstudio er et fint IDE (integrated development environment) til R. Nedenfor bruges R’s sample-funktion til at trække tilfældige tal.
(Helt til sidst i dette indlæg kan I finde den komplette R-kode. Nedenfor kommer koden med output.)
Først skal vi have repræsenteret kortbunken:
> # C: Clubs / klør
> # D: Diamonds / ruder
> # H: Hearts / hjerter
> # S: Spades / spar
> faces <- c("C", "D", "H", "S")
> nums <- c("A", 2:10, "J", "Q", "K")
>
> # Vores kortbunke: CA, C2, C2, ..., CQ, CK, DA, ..., DK, ...., SK
> # Denne genereres automatisk, men man kunne også gøre det manuelt:
> # pile_init <- c("CA", "C2") # Osv.
> pile_init <- unlist(lapply(faces, function(x) paste0(x, nums)))
>
> # De første 6 kort i bunken
> head(pile_init, n = 6)
[1] "CA" "C2" "C3" "C4" "C5" "C6"
>
> # De sidste 6 kort i bunken
> tail(pile_init, n = 6)
[1] "S8" "S9" "S10" "SJ" "SQ" "SK"
>
> # Antallet af kort i bunken
> length(pile_init)
[1] 52
Det er ikke så vigtigt hvordan bunken er blandet når vi går i gang. Vi skal egentlig bare holde styr på det sidste kort som her er “SK”.
Og så går vi i gang med at simulere 1,000 kortblandinger. Hver gang registrerer vi antallet af blandinger, der blev foretaget før bunken var blandet “nok”:
> # Funktion der simulerer én blanding
> simulate_process <- function() {
+ # Vi starter med en ny bunke
+ pile <- pile_init
+
+ # En tæller til antallet af blandinger
+ rifs <- 0
+
+ while (TRUE) {
+ # Registrer at der nu er bladet én gang mere
+ rifs <- rifs + 1
+
+ # Tilfældig position som topkortet skal hen til
+ top_pos <- sample(x = seq_along(pile), size = 1)
+
+ # Med sandsynlighed 1/52 ender det igen i toppen
+ if (top_pos == 1) {
+ #pile <- pile
+ } else if (top_pos == length(pile)) {
+ # Det kan også ende i bunden
+ pile <- c(pile[-1], pile[1])
+ } else {
+ # Eller et sted midt i mellem
+ pile <- c(pile[2:top_pos], pile[1], pile[-(1:top_pos)])
+ }
+
+ # Hvis topkortet er bundkortet;
+ # her kunne man også have skrevet
+ # if (pile[1] == "SK") {
+ # men dette virker også selvom man ændrer pile_init
+ if (pile[1] == pile_init[length(pile_init)]) {
+ break
+ }
+ }
+
+ # Topkortet (der er nu er det oprindelige bundkort)
+ # skal også blandes, men vi er ligeglade med hvor det ender
+ rifs <- rifs + 1
+
+ return(rifs)
+ }
>
> # Indstiller PRNG til samme tilstand for at kunne reproducere resultaterne
> set.seed(1)
>
> # Simulér processen 1,000 gange
> riffles <- replicate(1000, simulate_process())
>
> # De første 6 blandinger:
> head(riffles, n = 6)
[1] 249 191 205 280 189 314
>
> # Gennemsnittet af antal blandinger
> mean(riffles)
[1] 234.757
Som I kan se får vi også at der i gennemsnit skal 235 blandinger til.
Men vores simulationer gør os i stand til at finde og vise fordelingen af antal blandinger:
> # Estimer fordelingen
> rif_dens <- density(riffles)
>
> # Equal-tailed interval (begge haler har samme sandsynlighed)
> qs <- quantile(riffles, c(0.025, 0.975))
>
> # Find x-værdierne
> x1 <- min(which(rif_dens$x >= qs[1]))
> x2 <- max(which(rif_dens$x < qs[2]))
>
> # De centrale 95%
> rif_dens$x[c(x1, x2)]
[1] 144.2375 384.8943
>
> plot(rif_dens)
> polygon(x = c(rif_dens$x[c(x1, x1:x2, x2)]), y = c(0, rif_dens$y[x1:x2], 0), col = "gray")
> abline(v = mean(riffles), lty = 2)
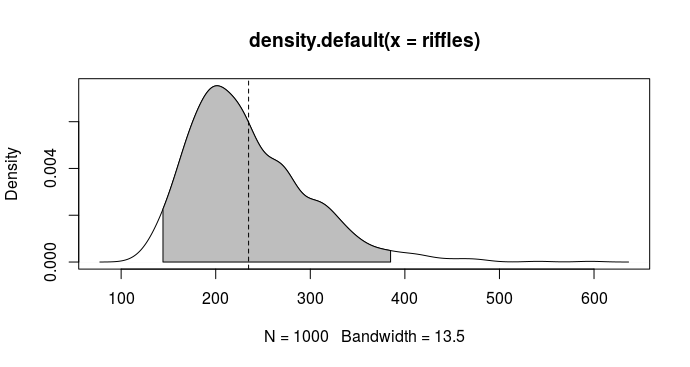
Altså vil man skulle forvente at skulle blande mellem 144 og 385 gange (og i gennemsnit 235) før at denne måde at blande på giver en bunke der er blandet nok.
(Hvilket nok er medvirkende til at jeg aldrig har set nogen praktisere denne form for kortblanding.)
Komplet R-kode:
# C: Clubs / klør
# D: Diamonds / ruder
# H: Hearts / hjerter
# S: Spades / spar
faces <- c("C", "D", "H", "S")
nums <- c("A", 2:10, "J", "Q", "K")
# Vores kortbunke: CA, C2, C2, ..., CQ, CK, DA, ..., DK, ...., SK
# Denne genereres automatisk, men man kunne også gøre det manuelt:
# pile_init <- c("CA", "C2") # Osv.
pile_init <- unlist(lapply(faces, function(x) paste0(x, nums)))
# De første 6 kort i bunken
head(pile_init, n = 6)
# De sidste 6 kort i bunken
tail(pile_init, n = 6)
# Antallet af kort i bunken
length(pile_init)
# Funktion der simulerer én blanding
simulate_process <- function() {
# Vi starter med en ny bunke
pile <- pile_init
# En tæller til antallet af blandinger
rifs <- 0
while (TRUE) {
# Registrer at der nu er bladet én gang mere
rifs <- rifs + 1
# Tilfældig position som topkortet skal hen til
top_pos <- sample(x = seq_along(pile), size = 1)
# Med sandsynlighed 1/52 ender det igen i toppen
if (top_pos == 1) {
#pile <- pile
} else if (top_pos == length(pile)) {
# Det kan også ende i bunden
pile <- c(pile[-1], pile[1])
} else {
# Eller et sted midt i mellem
pile <- c(pile[2:top_pos], pile[1], pile[-(1:top_pos)])
}
# Hvis topkortet er bundkortet;
# her kunne man også have skrevet
# if (pile[1] == "SK") {
# men dette virker også selvom man ændrer pile_init
if (pile[1] == pile_init[length(pile_init)]) {
break
}
}
# Topkortet (der er nu er det oprindelige bundkort)
# skal også blandes, men vi er ligeglade med hvor det ender
rifs <- rifs + 1
return(rifs)
}
# Indstiller PRNG til samme tilstand for at kunne reproducere resultaterne
set.seed(1)
# Simulér processen 1,000 gange
riffles <- replicate(1000, simulate_process())
# De første 6 blandinger:
head(riffles, n = 6)
# Gennemsnittet af antal blandinger
mean(riffles)
# Estimer fordelingen
rif_dens <- density(riffles)
# Equal-tailed interval (begge haler har samme sandsynlighed)
qs <- quantile(riffles, c(0.025, 0.975))
# Find x-værdierne
x1 <- min(which(rif_dens$x >= qs[1]))
x2 <- max(which(rif_dens$x < qs[2]))
# De centrale 95%
rif_dens$x[c(x1, x2)]
plot(rif_dens)
polygon(x = c(rif_dens$x[c(x1, x1:x2, x2)]), y = c(0, rif_dens$y[x1:x2], 0), col = "gray")
abline(v = mean(riffles), lty = 2)
 = \frac{19x^3}{3} - 38x^2 + \frac{212x}{3} - 38")
 = \frac{19 \cdot 1^3}{3} - 38 \cdot 1^2 + \frac{212 \cdot 1}{3} - 38 = \frac{19}{3} - 38 + \frac{212}{3} - 38 = \frac{19+212}{3} - 76 = 77 - 76 = 1") . Waw! Og så videre for 2 og 3. Prøv fx ved hjælp af
. Waw! Og så videre for 2 og 3. Prøv fx ved hjælp af