I dette indlæg vil jeg først vise noget grafik. Sidst i indlægget vil jeg give nogle links til nogle gode foredrag om grafik.
DR.dk bringer i dag artiklen “Ny måling: Danskerne har mest sympati med lønmodtagerne“. I den er der følgende graf:
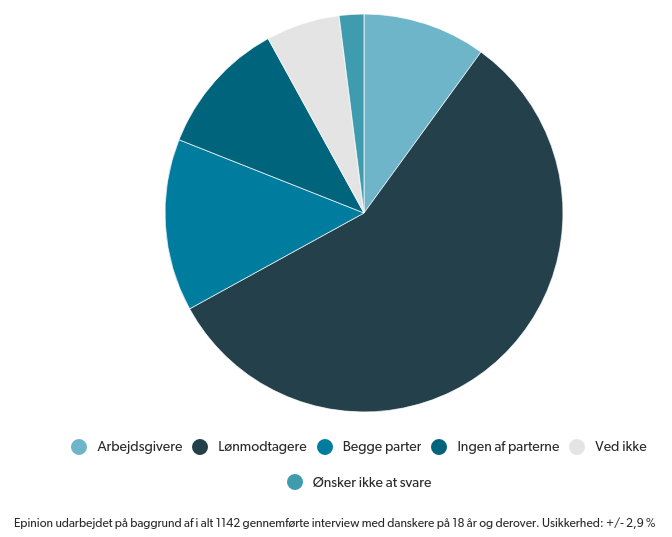
(Kilde: DR.dk “Ny måling: Danskerne har mest sympati med lønmodtagerne“)
Min umiddelbare reaktion var: “Den graf er godt nok svær at tyde!”.
Der er flere problemer med den. For det første er cirkeldiagrammer/lagkagediagrammer svære at tyde – forstået på den måde, at det er svært at sammenligne størrelsen på de forskellige “lagkagestykker”. Hvor mange gange større er et stykke i forhold til et andet stykke? For det andet er farvevalget måske ikke velegnet til denne type graf, hvis man gerne vil bruge den til at illustrere forholdene mellem de forskellige svarmuligheder. Man kan (meget groft) dele farveskalaer op i to grupper: sekventielle (fra lyseblå til mørkeblå, fra rød til grøn osv.) eller kvalitative. De sekventielle bruges ofte til at illustrere en talværdi (fx indkomst) og de kvalitative bruges ofte til grupper (fx køn eller region).
Så alt i alt er grafen svær at tyde pga. både typen og farvevalget. Det skal dog siges, at man inde på artiklen kan køre musen over “lagkagestykkerne” for at få hjælpetekst og andelen oplyst. (Men man kan spørge om interaktivitet virkelig er nødvendig til at illustrere dette data.)
Til denne type grafer, vil man typisk anvende søjlediagrammer som fx:
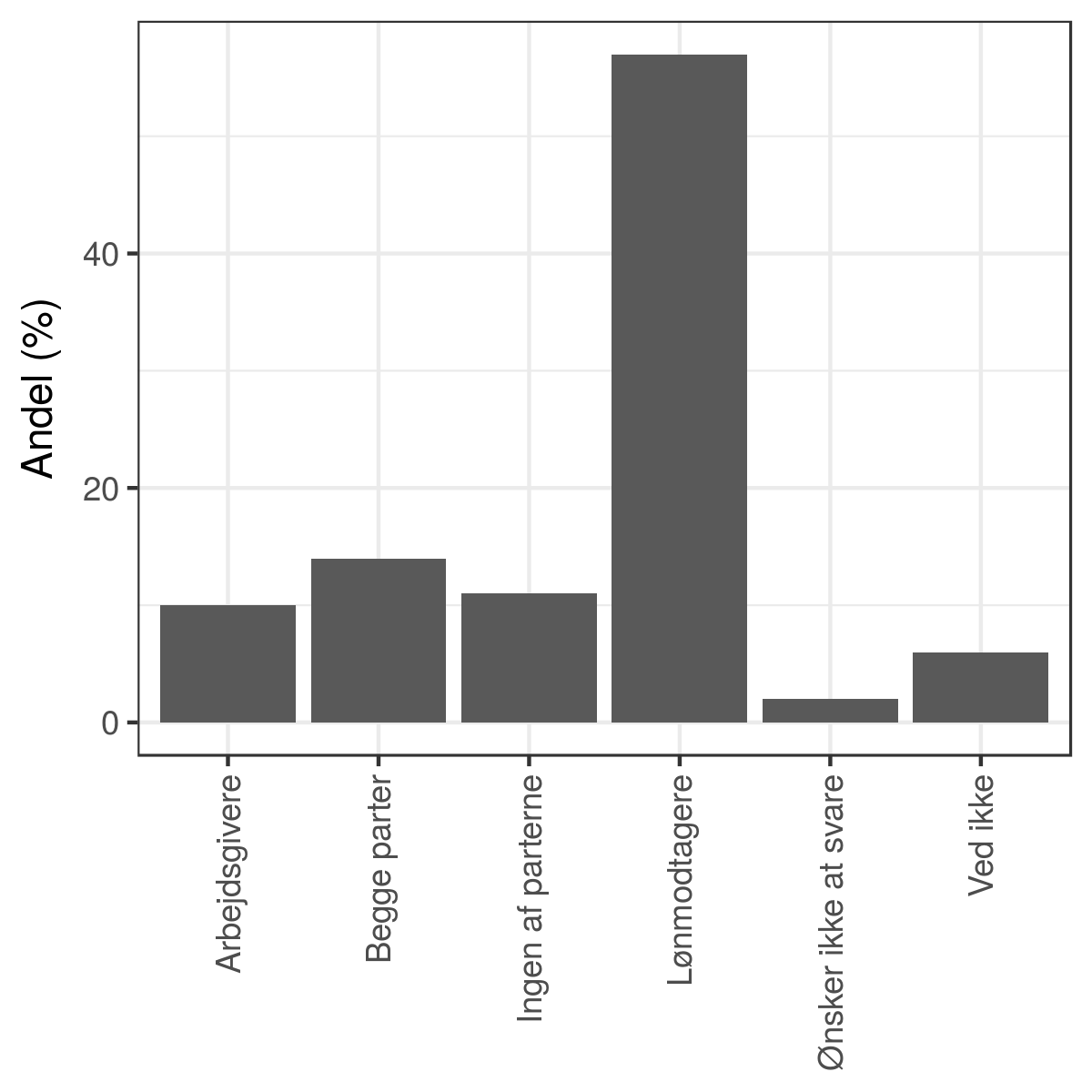
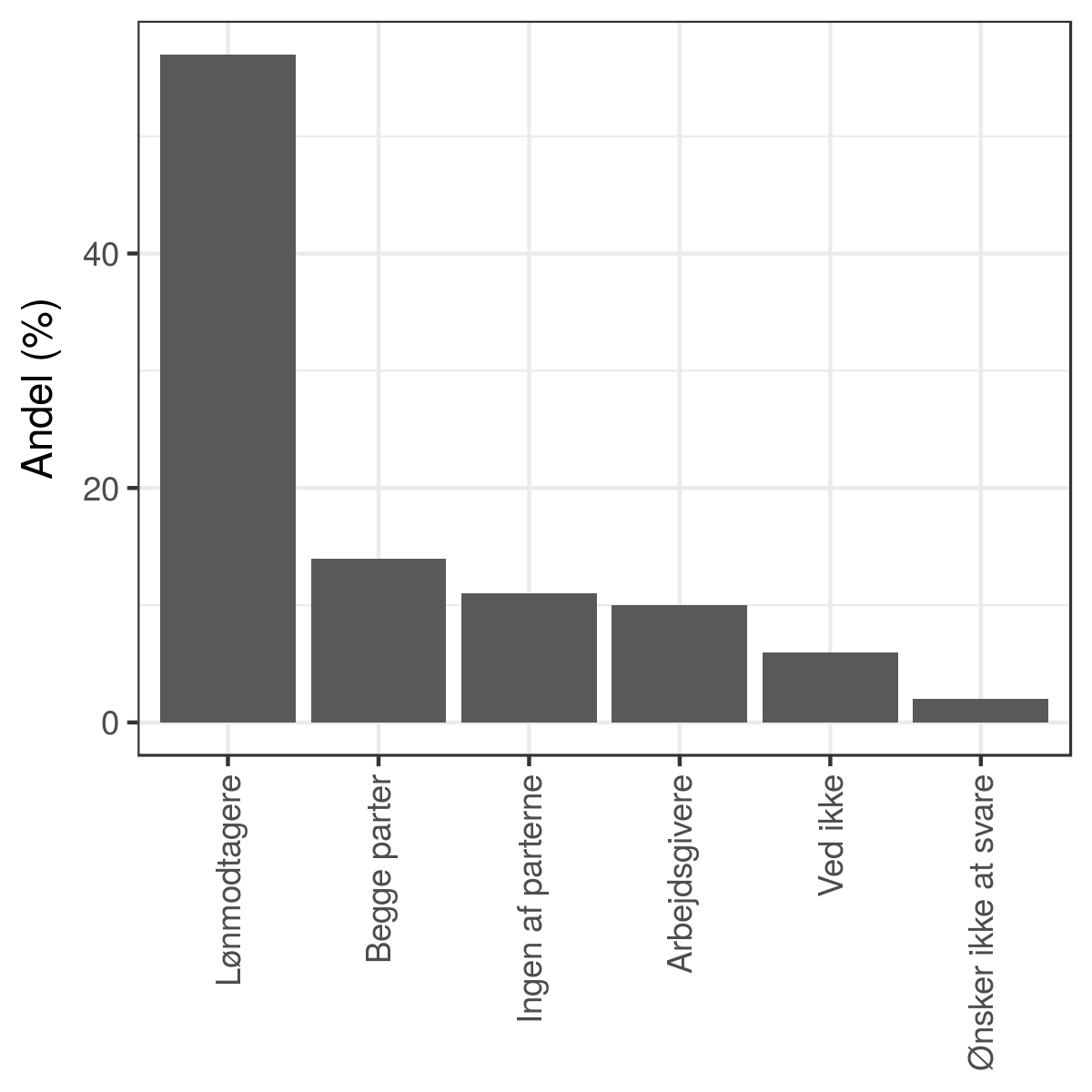
Her er et par varianter. Først hvor søjlerne ordnes efter værdi:
Og vil man gerne have farver på, kan man da godt det:
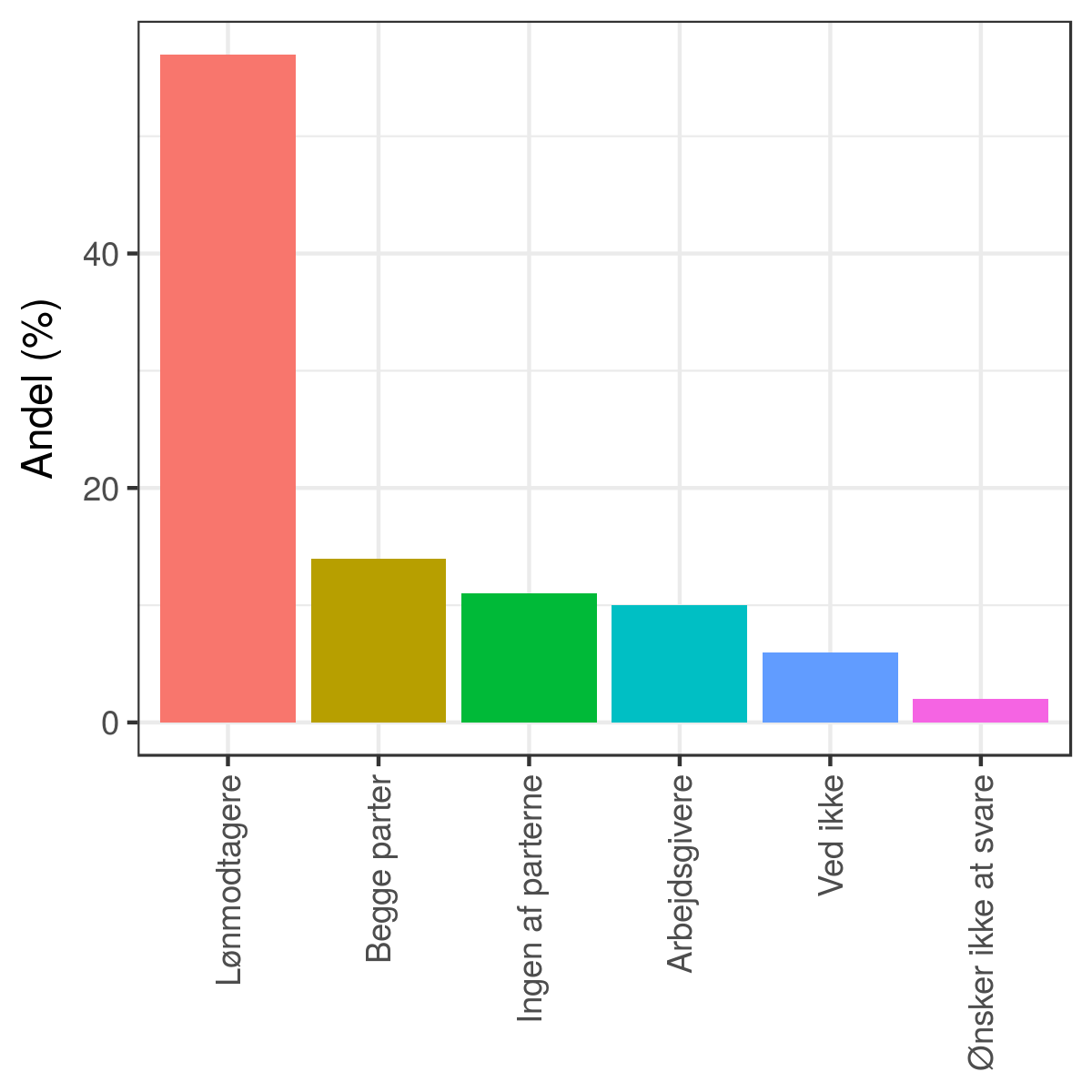
Jeg vil påstå, at sådanne grafer er bedre til at hjælpe mig med at sammenligne svarmulighederne end cirkeldiagrammet er.
Det leder frem til det næste: Der er meget psykologi i grafik. Det handler ikke kun om statistik og om rent teknisk at få produceret noget grafik.
Og det er svært at lave god grafik!
Der forskes stadigvæk i, hvordan grafik tolkes – og om der er forskel mellem folkeslag. Fx er farver en oplagt del af grafik: Men man kan være farveblind og det kan man endda være på mange måder. Derfor er det vigtigt at producere grafik som også farveblinde kan læse – men det er ikke let. Og der kan muligvis også være forskel på, hvordan forskellige kulturer opfatter farver.
Auckland University (i New Zealand) har afholder hvert år en foredragsrække kaldet Ihaka lectures. Den blev første gang afholdt i 2017 og hver række består af 3 foredrag i marts måned. I år var der følgende tre foredrag:
- “Myth busting and apophenia in data visualisation: is what you see really there?” med Dianne Cook. Link til foredraget på YouTube.
- “Making colour accessible” med Paul Murrell. Link til foredraget på YouTube.
- “Visual trumpery: How charts lie – and how they make us smarter” med Alberto Cairo. Link til foredraget på YouTube.
Alle disse tre foredragsholdere er kendte og gode. Jeg vil ikke bruge tid på at præsentere dem hver især her. Se i stedet deres foredrag. Men de alle illustrerer fint det sammenspil der er mellem statistik og psykologi når man laver visualiseringer/illustrationer/grafik.
Relateret til dette indlæg er måske specielt nr. 3 af Alberto Cairo. Han giver en masse gode eksempler på dårlig grafik. Ikke nødvendigvis åbenlys dårlig grafik, men grafik der kan vildlede læseren.
Di Cook (nr. 1 ovenfor) forklarer i sit foredrag også om, hvordan kan kan bruge visualiseringer til statistisk inferens i stedet for den traditionelle tilgang med hypotesetest. De har lavet forsøg med at lade folk vurdere visualiseringer, der er lavet med udgangspunkt i nulhypotesen og så se om folk kan genkende det observerede datasæt. Hvis de kan det, “stikker det ud” og kommer så måske ikke fra den model, man har specificeret i nulhypotesen. Der er muligvis nogle problemer med denne tilgang – fx er det ikke åbenlyst hvad den alternative hypotese er. Derudover er det svært at vælge teststatistik/teststørrelse (der i dette tilfælde svarer til typen af grafik brugeren skal vurdere, fx scatterplot, barplot osv.). Men det er bestemt interessant at høre om denne vinkel på statistisk inferens.