De såkaldte Ancestry Informative Markers (AIMs) er genetiske markører som indeholder en høj grad af information omkring en persons genogenetiske ophav. Med genogenetisk menes der genetiske markører som relaterer sig til geografisk lokation af subpopulationer. Vi ved at mange fænotypiske træk (fx hud- og hårfarve) er defineret af genetiske markører, mens andre markører ikke nødvendigvis manifesterer sig i umiddeltbart synlige træk.
Det humane genom består af over 3 milliarder nukleobaser angivet ved bogstaverne A, C, G og T. Store dele af genomet er identisk for alle mennesker – idet dette netop gør os til homo sapiens. Den simpleste form for afvigelser er de såkaldte Single Nucleotide Polymorphisms (SNPs), som er enkelt position på genomet hvor fx mindst 1% af populationen har en alternativ base. Fx kunne A være den oprindelige tilstand for en markør mens C er en muteret tilstand. Sådanne markører er interessante fra et populationsgenetisk synspunkt idet fx alle afrikanere kunne have genotypen AA (et A fra mor og et A fra far) mens alle asiater er CC. Ved at benytte informationen fra flere af sådanne markører er det muligt at fastslå hvor det er mest sandsynligt at person kommer fra.
I retsgenetik, som er disciplinen hvor DNA benyttes i en retlig sammenhæng (fx straffe-, faderskabs- og familiesammenføringssager), rapporteres beviset typisk i form af et likelihood ratio, dvs. man evaluerer hvor sandsynligt bevismaterialet (her DNA profilen) er under to stridende hypoteser. Lad 



hvor ")
")

}{P(E \mid H_A)},")
Problemet vi har fokuseret på i vores forskning (link til artikel i Theoretical Population Biology) er hvorledes man håndterer situationen hvor en konkret DNA profil stammer fra en subpopulation hvor fra vi endnu ikke har en stikprøve af DNA profiler. Fx hvis profilen  = 10^{-2} = 0.01")


At den relative hyppighed er stor betyder ikke nødvendigvis at DNA profilen stammer fra populationen med den største profil-sandsynlighed. Vores løsning var at fokusere på hvornår er en profil for sjælden i en given population? I statistiske termer kan dette oversættes til: er profilen en outlier i den givne population? Denne tilgang gør det muligt at konkludere at der ikke findes en relevant population i det tilgængelige reference materiale. Fx hvis en given profil bliver erklæret outlier i samtlige tilgængelige populationer konkluderes det at profilen stammer fra en endnu ikke undersøgt population (eller evt. har et mere kompliceret genetisk ophav – fx med forældre med vidt forskellige genogenetiske baggrund).
På kortet nedenfor ses lokationen for de populationer som er inkluderet i reference materialet. Farven af hvert punkt angiver om profilen er blevet erklæret som outlier (blå) eller ej (rød). Profilen er i dette tilfælde fra Grønland og konklusionen er derfor korrekt.
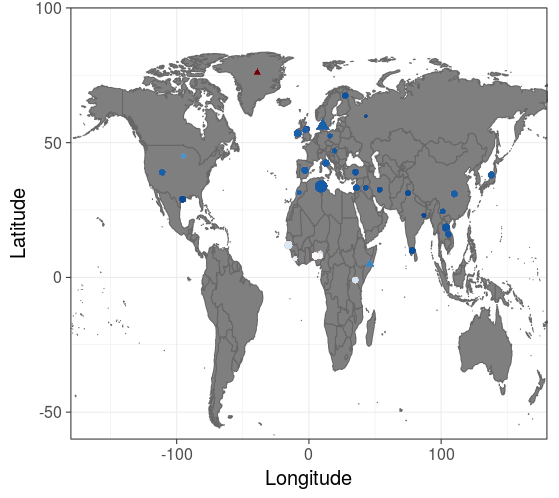
Lokation af populationerne. Farven indikerer beslutning omkring outlier (blå) eller ej (rød)
I plottet herunder vises profil hyppighederne for de forskellige populationer. Igen er det tydeligt at profilen er hyppigst forekommende i Grønland,  = 10^{-37}")



Genotype sandsynligheder af den grønlandske profil. Punkterne er estimatet og linjer angiver usikkerheder.