OK titlen er på onkelhumor-niveau. Jeg kunne ikke lade være. Det, jeg vil fortælle jer om, er matematikken bag kortprojektioner, altså at lave en god repræsentation af (en del af) den runde jord på et kort, som jo er fladt.
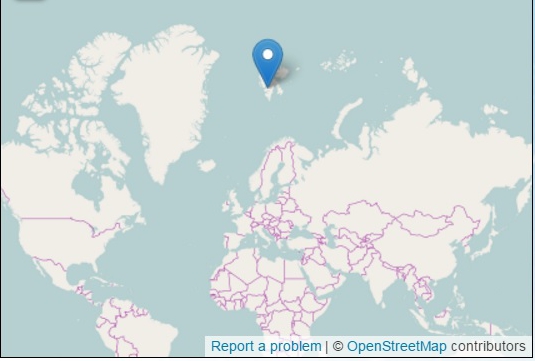
Her ligger Svalbard.
Da Politiken i december skulle vise læserne, hvor Svalbard ligger, brugte de dette kort. Det er rigtig nok, at Svalbard ligger der, hvor den blå pil er. Men det er alligevel ikke helt godt. Der er noget med størrelsesforhold: Svalbard ser ud til at være på størrelse med Storbritannien. I virkeligheden er Svalbard 61.000 km^2 og Storbritannien er 4 gange så stort. Der er også et problem med retninger. Hvor kommer man hen, hvis man flyver stik nord fra Svalbard og fortsætter i den retning (stik syd, når man passerer Nordpolen)? Det kan man ikke se her – Nordpolen er strakt ud til en ret linje i dette kort. Kortet er lavet i Mercatorprojektionen. Her kan man lege med arealer i Mercatorprojektionen.

“Stereographic projection SW” by Strebe – Own work. Licensed under CC BY-SA 3.0 via Commons –
Her er en anden fremstilling af, hvor Svalbard ligger. Det er lidt gnidret, men giver et bedre indtryk af, hvor områder tæt på Nordpolen ligger i forhold til hinanden. Man kan nu se, at en tur stik nord fra Svalbard vil ende et sted i Alaska. Der er stadig problemer med arealerne. Projektionen er en stereografisk projektion.

Google Earth. Nordpolen i centrum.
Google Earth giver et andet billede – men man får igen et meget bedre indtryk af områder tæt på Svalbard.
Hvad er så det bedste kort? Det er ikke så svært at indse, at man får problemer, hvis man vil vise hele Jorden i et enkelt kort. Man er i hvert fald nødt til at lave et hul et sted, før overfladen af Jorden kan strækkes ud i planen. (Hvis man vil ikke vil have flere punkter på Jorden til at ligge oveni hinanden i kortet.)
Her er den matematiske formulering af, hvad et kort er: Man kan give punkterne på Jorden geografiske koordinater (længdegrad, breddegrad)=")
=(x(\lambda,\varphi),y(\lambda,\varphi))")
=(\lambda,\ln(\tan(\frac{\pi}{4}+\frac{\varphi}{2})))")
Google Earth – kortet er sådan cirka
=(\cos(\varphi)\cos(\lambda),\cos(\varphi)\sin(\lambda))")
Og Stereografisk projektion er
=\frac{2\cos\varphi}{1+\sin\varphi}(\cos(\varphi)\cos(\lambda),\cos(\varphi)\sin(\lambda))")
I alle tre eksempler, kan man skalere svarende til at squeeze på mobiltelefonen. Det svarer til at gange begge koordinater med en konstant (x,y) -> (kx,ky). Det ændrer ikke på de fundamentale egenskaber ved kortene. Nu kan vi regne på egenskaber ved kort og på et mere overordnet niveau spørge: Findes der kort, som opfylder xxx? Her er nogle spørgsmål og svar:
- Findes der kort, der bevarer forholdet mellem arealer af landområder? Svar. Ja. (Se nederst for et eksempel)
- Findes der kort, der bevarer vinkler? Svar: Ja. (Både Mercatorprojektion og Stereografisk projektion gør dette.)
- Findes der kort med konstant målestoksforhold? Nej.
- Findes der kort, som opfylder både 1 og 2? Nej.
3 og 4 siger, at der ikke findes et ideelt kort. Man må vælge det, der passer til formålet. Jeg vil ikke give et fuldt argument for 3 og 4 – det kan I jo komme til et af mine foredrag og høre om… Grundlæggende er problemet, at Jordens krumning forhindrer det.
Et kort argument for 3: Forsøg at lave sådan et kort med Nordpolen i centrum. lad os sige, det skal have målestoksforhold m. De punkter på Jorden, hvis afstand til Nordpolen er 50 km (afstand langs med Jordens runde overflade). skal i kortet have afstand 


I Danmark har vi flere kort i spil. De er allesammen vinkelbevarende, da det er væsentligt for opmåling og gør, at “facon” bevares nogenlunde (og da man ikke kan få alting…): Mercatorprojektionen bruges til havområderne, og for landområderne har vi Transversal Mercator Projektion – Mercatorprojektion, hvor man først har drejet kuglen, så en længdegrad er lagt ned på Ækvator. Man skal vælge to ting: Hvilken længdegrad skal være i midten – midtemeridianen og hvad er variationen, afvigelsen fra hovedmålestoksforholdet (målestoksforholdet er jo ikke konstant, men hvor galt må det gå) det fortæller implicit, hvor bredt kortet bliver. I Danmark har vi UTM med målestoksvariation 



Vi har også DKTM, Dansk Transversal Mercator. Der er 4 Zoner med en målforholds afvigelse på maksimalt 
I Danmark vedligeholdes kort af Geodatastyrelsen og der kan man også læse lidt om matematikken bag. Noget af det, de skriver, kan jeg kende fra mit eget kursus for landinspektørstuderende, men det har en hel generation af landinspektører også været igennem. Og de bliver jo også ansat i Geodatastyrelsen. Lige nu kan jeg faktisk ikke finde noget som helst om teorien bag kort, referencenet etc. på deres hjemmeside, men det er måske fordi de er ved at flytte hele molevitten til Aalborg, så de har nok at se til.

Archimedes’ arealbevarende cylinderprojektion,
Her er en arealbevarende projektion. Som I kan se, er der problemer med faconen på områderne til gengæld.




 .
.
\cdot i \cdot 3") er en faktorisering). Et Gaussisk heltal, som ikke kan skrives som et produkt af andre, er et Gaussisk primtal.
er en faktorisering). Et Gaussisk heltal, som ikke kan skrives som et produkt af andre, er et Gaussisk primtal.\cdot(2-i)=2^2-i^2=5") . Men 7 er. Figur 2 viser de Gaussiske primtal som punkter i planen.
. Men 7 er. Figur 2 viser de Gaussiske primtal som punkter i planen.
 altså c går op i
altså c går op i  i vores nye talsystem. Det skriver man
i vores nye talsystem. Det skriver man  . Hvis nu d faktisk har en heltallig kvadratrod
. Hvis nu d faktisk har en heltallig kvadratrod  er det særlig nemt – man lader bare z=0.
er det særlig nemt – man lader bare z=0. (altså om
(altså om  hvor $z$ er et Gaussisk heltal.
hvor $z$ er et Gaussisk heltal.



\geq K") når blot
når blot  . Det er nemlig det, vi mener med, at funktionen går mod uendelig for x gående mod uendelig.
. Det er nemlig det, vi mener med, at funktionen går mod uendelig for x gående mod uendelig.\geq K") og
og \geq\ln(M)\geq K")
)") , så vi kan altså vælge
, så vi kan altså vælge  .
. er mindre end 3
er mindre end 3>\ln(3)>\ln(e)=1")
 . For alle
. For alle  har vi
har vi >\ln(4^K)=K\ln(4)>K") .
.") er gode.
er gode. kommer tættere og tættere på
kommer tættere og tættere på  jo flere led, der tages med. Mere præcist, så er det sådan, at uanset hvor lille et tal
jo flere led, der tages med. Mere præcist, så er det sådan, at uanset hvor lille et tal  , min værste fjende vælger, så vil jeg kunne finde et (måske meget stort) tal N, så
, min værste fjende vælger, så vil jeg kunne finde et (måske meget stort) tal N, så  ligger mellem
ligger mellem  og
og  og det gør
og det gør  også, når
også, når  .
.

 – ved at lægge flere og flere tal sammen i denne sum – det går nu ret langsomt i forhold til andre metoder, som også bygger på, at noget “går mod” noget med $latex\pi$.
– ved at lægge flere og flere tal sammen i denne sum – det går nu ret langsomt i forhold til andre metoder, som også bygger på, at noget “går mod” noget med $latex\pi$.
^n\frac{1}{n}+\cdots = \ln{2}") , den naturlige logaritme til 2. Bemærk, at nogle led bliver lagt til, andre trukket fra, så efterhånden som flere led lægges til, skyder man skiftevis over og under
, den naturlige logaritme til 2. Bemærk, at nogle led bliver lagt til, andre trukket fra, så efterhånden som flere led lægges til, skyder man skiftevis over og under ") , men mindre og mindre over og under.
, men mindre og mindre over og under. kaldes en afsnitssum. En række er altså ikke selv en sum, men en opskrift på afsnitssummer.
kaldes en afsnitssum. En række er altså ikke selv en sum, men en opskrift på afsnitssummer. , grundtallet for den naturlige logaritme.
, grundtallet for den naturlige logaritme. Der er flere forskellige argumenter for, at den divergerer: Et går via sammenligning med et integrale:
Der er flere forskellige argumenter for, at den divergerer: Et går via sammenligning med et integrale: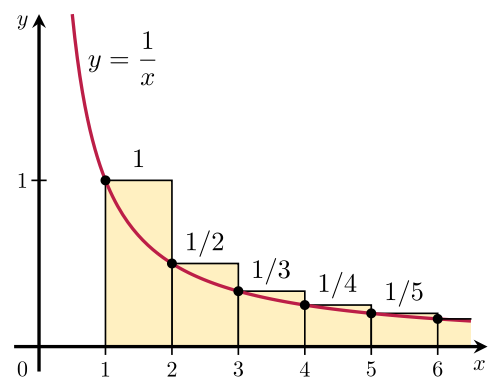
-\ln(1)=\ln(M)") . Det går mod uendelig. Så den harmoniske række er divergent. Men det går langsomt mod uendelig. Meget, meget langsomt.
. Det går mod uendelig. Så den harmoniske række er divergent. Men det går langsomt mod uendelig. Meget, meget langsomt. år. Et år har 31 556 926 sekunder, ca.
år. Et år har 31 556 926 sekunder, ca.  (nogen siger
(nogen siger  for at huske det). Det er altså
for at huske det). Det er altså  sekunder. Tag den naturlige logaritme (
sekunder. Tag den naturlige logaritme (=\ln(4,3)+17\times ln(10)") og se, at Kevin har ret – Intervallet, Kevin har med, er en kombination af, at tidspunktet for Big Bang ikke er helt klart, og at den harmoniske række er større end det integrale, vi her regner på.
og se, at Kevin har ret – Intervallet, Kevin har med, er en kombination af, at tidspunktet for Big Bang ikke er helt klart, og at den harmoniske række er større end det integrale, vi her regner på. ikke har løsninger hvor både x, y og z er hele tal og
ikke har løsninger hvor både x, y og z er hele tal og  . (Den er bevist, men det tog 300 år). Andre store formodninger er Riemannhypotesen (ikke bevist) og Poincare-formodningen (er bevist). De spiller rollen som pejlemærker for matematikere og som sten i skoen – det er rigtig irriterende ikke at kunne bevise noget, man er ret sikker på, er rigtigt. Og så giver de ofte anledning til løsning af andre resultater i forbifarten – for at få skovlen under et svært resultat, må man ofte opdage(opfinde) nye matematiske metoder, som kan vise sig at være vigtige for noget, man slet ikke havde regnet med. Wikipedia har en
. (Den er bevist, men det tog 300 år). Andre store formodninger er Riemannhypotesen (ikke bevist) og Poincare-formodningen (er bevist). De spiller rollen som pejlemærker for matematikere og som sten i skoen – det er rigtig irriterende ikke at kunne bevise noget, man er ret sikker på, er rigtigt. Og så giver de ofte anledning til løsning af andre resultater i forbifarten – for at få skovlen under et svært resultat, må man ofte opdage(opfinde) nye matematiske metoder, som kan vise sig at være vigtige for noget, man slet ikke havde regnet med. Wikipedia har en 
^{1+\varepsilon}<c")
 . Primtallene kan “genbruges”. abc-formodningen drejer sig om de forskellige primtal, der bruges, og ikke hvor mange gange, de genbruges. Man tager så produktet af disse. Det kaldes radikalet. Eksempelvis er
. Primtallene kan “genbruges”. abc-formodningen drejer sig om de forskellige primtal, der bruges, og ikke hvor mange gange, de genbruges. Man tager så produktet af disse. Det kaldes radikalet. Eksempelvis er
 uanset hvor lille dette
uanset hvor lille dette ^2<c") .
.}{\log(rad(abc))}")
 er kompleksiteten O(
er kompleksiteten O( ) og man er ikke interesseret i konstanten 32 eller leddene med lavere grad.
) og man er ikke interesseret i konstanten 32 eller leddene med lavere grad.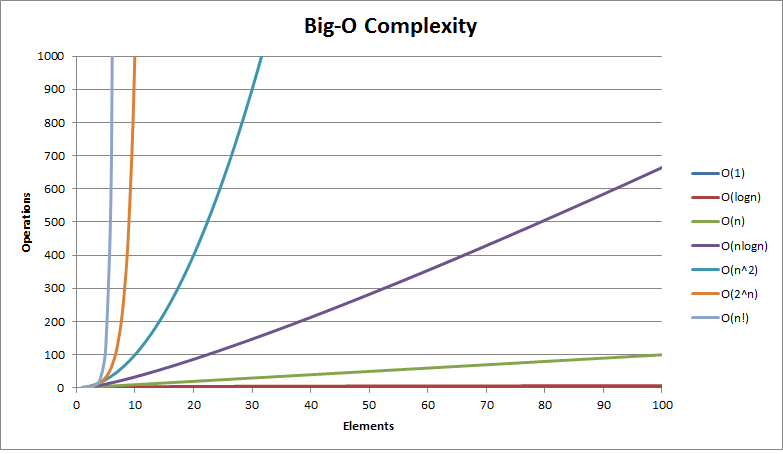
 , altså eksponentiel (
, altså eksponentiel ()") Grafisomorfiproblemet beskriver sin egen kompleksitetsklasse GI, som er alle problemer, man ved har samme kompleksitet som grafisomorfiproblemet – fordi man kan formulere det at løse det ene beslutningsproblem som et spørgsmål indenfor løsning af det andet problem og omvendt. Grafisomorfialgoritmerne har man hidtil haft i en klasse for sig, hvor man ikke har vidst, hvor de hører til. Det åbne spørgsmål er, om der findes en algoritme med polynomiel tidskompleksitet, der altid korrekt kan fortælle, om to grafer er isomorfe. Altså en algoritme, hvis tidskompleksitet er et polynomium. Og det må gerne være et 2000-grads polynomium. Men man har ikke været i nærheden af at have en sådan algoritme. Man vidste, man kunne lave en, der er højst
Grafisomorfiproblemet beskriver sin egen kompleksitetsklasse GI, som er alle problemer, man ved har samme kompleksitet som grafisomorfiproblemet – fordi man kan formulere det at løse det ene beslutningsproblem som et spørgsmål indenfor løsning af det andet problem og omvendt. Grafisomorfialgoritmerne har man hidtil haft i en klasse for sig, hvor man ikke har vidst, hvor de hører til. Det åbne spørgsmål er, om der findes en algoritme med polynomiel tidskompleksitet, der altid korrekt kan fortælle, om to grafer er isomorfe. Altså en algoritme, hvis tidskompleksitet er et polynomium. Og det må gerne være et 2000-grads polynomium. Men man har ikke været i nærheden af at have en sådan algoritme. Man vidste, man kunne lave en, der er højst })") , hvor n er antal knuder. Den kompleksitet kaldes subeksponentiel – ikke polynomiel, men heller ikke så voldsom, at den er eksponentiel. Den algoritme er fra 1983, så det er derfor, der er røre i andedammen, når der kommer nyt.
, hvor n er antal knuder. Den kompleksitet kaldes subeksponentiel – ikke polynomiel, men heller ikke så voldsom, at den er eksponentiel. Den algoritme er fra 1983, så det er derfor, der er røre i andedammen, når der kommer nyt.)^c)") hvor c er en konstant. Det er “quasipolynomielt” og klart mindre end det tidligere opnåede. Konstruktionen af algoritmen har involveret resultater fra det matematiske område gruppeteori.
hvor c er en konstant. Det er “quasipolynomielt” og klart mindre end det tidligere opnåede. Konstruktionen af algoritmen har involveret resultater fra det matematiske område gruppeteori. . Heldigvis bruger vi Fast Fourier Transform, som er
. Heldigvis bruger vi Fast Fourier Transform, som er ") , og så er der Vild med Dans på skærmen.
, og så er der Vild med Dans på skærmen.{kind=link}