To australske dataloger har fundet en begrænset algoritme, som deler kager og andet, man vil dele, misundelsesfrit. Det skriver Erika Klarreich om i Quanta Magazine. Jeg har tidligere skrevet om den type problemer på Numb3rsbloggen, så jeg tillader mig at kopiere mig selv. Opdelinger med forskellige mål for, hvad en ideel deling er, optræder eksempelvis i økonomi – der optræder “nyttefunktioner”, som er mål for, hvor meget mere tilfreds, bestemte personer bliver, hvis de køber dette eller hint. Her deler vi kager, men I må gerne tænke på andre mere økonomiske ting – løn, ferie,…:
Kageudskæringsalgoritmer:
Det handler groft set om at dele noget – en kage eller noget andet – i et antal stykker, så alle bliver tilfredse. Et mere avanceret og kompliceret eksempel er opdeling af landområder efter en krig.
Et eksempel på en kageudskæringsalgoritme er “du deler og din søster vælger først” algoritmen, som forældre i hele verden nok kender. Ideen er, at hvis jeg deler, må jeg mene, begge stykker er lige gode. Og jeg er altså tilfreds, uanset hvilket stykke hun vælger. Omvendt er hun tilfreds, for hun får det stykke, hun selv mener ser bedst ud.
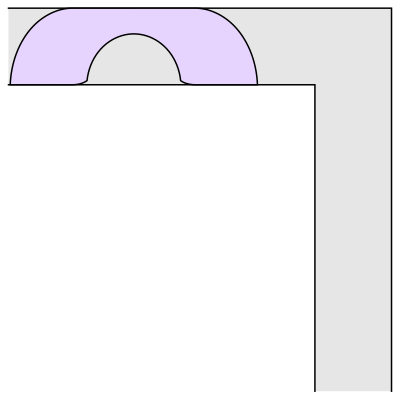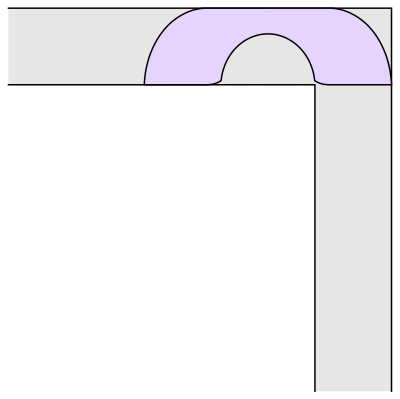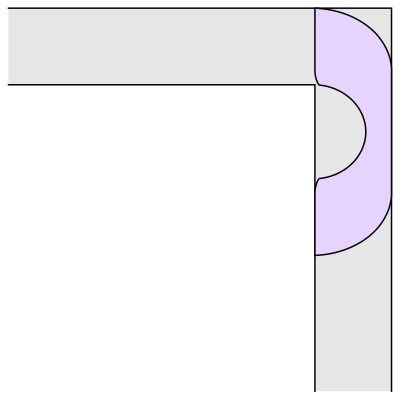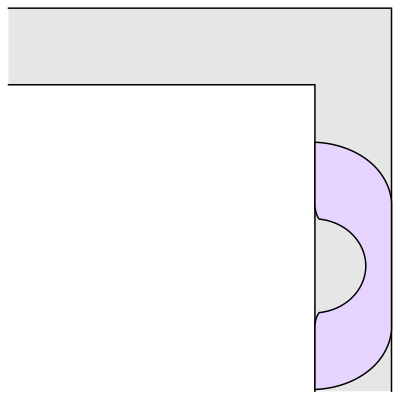
Man forestiller sig, en kage skal deles mellem personer, som har forskellige præferencer; Charlie viste en lagkage med vanille og chokolade og med glasur. Nogen sætter meget pris på glasur, andre mindre, nogen er vilde med vanille, andre med chokolade.
Vi forestiller os altså, at et stykke af kagen kan have forskellig værdi for forskellige personer. Og hele kagen kan være mere værd for en person end for en anden. Lad os sige, der er n personer, der skal dele kagen.
Man kan stille mange forskellige krav til en deling – hvad betyder det, at den er rimelig. Det kunne være
1) Proportionalt – hver person mener, at værdien af deres eget stykke er mindst 1/n af den samlede værdi. (OBS. Hvis nu jeg bedst kan lide vanilje og min søster chokolade og kagen består af halvt af hver, kan vi begge to få mere end halvdelen af det, vi mener er den samlede værdi. Ved at lade mig få den halvdel, der er vanilje og hun får den anden.)
2) Misundelsesfrit: Hver person mener, hun har fået det bedste af de stykker, kagen er delt i. (Ikke en skarp ulighed – det er nok, at der ikke er et andet, hun hellere vil have.)
3) Pareto optimalt:Vi har en opdeling, hvor enhver anden opdeling, hvor en deltager får mere, vil medføre, at en eller flere får mindre. Begrebet er en slags stabilitet overfor ændringer og optræder ofte i økonomi. Hvis jeg skal overbevise de andre om at lave det om, skal jeg overtale en deltager til at få mindre. (Det er det, der starter krige)
4) Ligeligt: Alles stykker har samme værdi. Så værdien af mit stykke for mig, er det samme som værdien af min søsters stykke for hende. Det kræver, at man kender alle deltagernes værdisætning af kagen.
Lad os begynde med to personer, som har et snit til at dele kagen. Vi vil ikke have en deling, hvor man tillader så mange stykker, at det ender med, at hver får en bunke krummer. Med “du deler, din søster vælger” algoritmen bliver delingen proportional og misundelsesfri men ikke nødvendigvis ligelig og pareto optimal.
Eksempel: Halvdelen af kagen er vanilje, halvdelen chokolade. Jeg er vild med chokolade, min søster med vanilje. jeg skærer og ved ikke, at min søster helst vil have vanilje. Så for en sikkerhedsskyld deler jeg, så begge stykker har halvt chokolade og halvt vanilje. Vi ville begge to have foretrukket delingen hvor jeg fik kun chokolade, og min søster kun vanilje – det er altså ikke pareto optimalt.
Lad os kigge nærmere på betingelserne ligelig og misundelsesfri. Pareto optimal er en lidt pudsig betingelse her, for hvis jeg får det hele, kan min søster ikke forbedre sin situation, uden jeg får mindre, end jeg havde; det er altså Pareto optimalt – og nok er jeg storesøster, men mon ikke FN eller forældre ville gribe ind.
Ligelig opdeling giver kun mening, hvis alle deltagere har samme samlede værdi af kagen, og man antager også, at alle sætter værdien af nok så små stykker højere end 0. Hellere chokolade end slet ingen kage. Lad os sige, den samlede værdi er 1.
En yderligere forsimpling er, at man kun må skære i en på forhånd valgt retning ( Tænk på en langstrakt skærekage, hvor man skærer på tværs – ikke noget med kagemænd, hvor man kan foretrække en af fødderne).
Vi kalder midtpunktet af kagen 1/2 og siger, man kan skære i punkter fra 0 til 1 (kagen er 1 lang). Fra 0 til 1/2 er der chokolade og fra 1/2 til 1 er der vanilje. (Vi antager, at stykker med areal 0, ikke har nogen værd, så det er ligemeget, hvad der er i 1/2.)
Hvis nu A er dobbelt så vild med chokolade som med vanilje, er hans værdisætning 4/3⋅x for et stykke af længde x med chokolade. Den er 2/3⋅ x for et stykke med vanilje. Vi antager, B har det omvendt.
Hvis A skal dele, vil hans strategi være, at det stykke, han ender med, har værdi mindst 1/2. (En minimax strategi – man satser ikke, men sørger for, at få mest muligt ud af det værste, der vil kunne ske.)
Så han deler i punktet p=3/8. Han har kun chokolade på stykket til venstre for p, så det har værdi
3/8 ⋅ 4/3 = 1/2
B vil vælge stykket til højre og få en værdi på 3/4, så det er ikke ligeligt, og A har snydt sig selv.
Havde A delt i midten, ville B stadig vælge stykket til højre, begge ville få værdi 2/3, og det ville være ligeligt og misundelsesfrit.
For n = 3 eller flere, kan man vise, at der findes situationer, hvor man ikke med n-1 snit kan lave en misundelsesfri og ligelig deling. Se f.eks. Better ways to cut a cake S. Brams, M.A. Jones og C. Klamler, Notices of the AMS, Vol 53 no. 11. Husk, hvis du går igang med den, at det handler om strategier og algoritmer: Hvordan ser det ud, hvis A ikke er ærlig om sin værdifunktion; er der en udenforstående involveret (FN eller andre) etc.
I How to cut a cake fairly, Walter Stromquist, American Mathematical Monthly, Vol 87, No.8, Oct. 1980, pp 640-644 (findes på Jstor for dem, der har adgang til det), bevises, at der eksisterer en misundelsesfri opdeling med n-1 snit for n deltagere. Men der er ikke en algoritme til at finde den. Det er et meget smukt argument (jo, det er det altså).
En opdeling i n+1 stykker betragtes som en stribe snit x1,x2,…,xn hvor 0 ≤ x1 ≤ x2 … ≤ xn ≤ 1. Det er de steder i intervallet mellem 0 og 1, hvor der skæres. Det tænker man så på som et punkt (x1,x2,…,xn) i et n-dimensionalt rum.
Las os begrænse os til at dele i tre stykker. Punkterne (x1,x2) vil ligge i en trekant i planen med hjørner (0,0), (0,1) og (1,1). Så hvert punkt svarer til en opdeling.
Hjørnepunkterne svarer til, at der to “stykker” uden noget, og et stykke, der er hele kagen. Kald de tre stykker, der kommer ud af opdelingen for nummer 1, 2 og 3 for stykket mellem 0 og x1, mellem x1 og x2 og mellem x2 og 1. Så er (0,0) der, hvor stykke 3 udgør hele kagen. (0,1) er, hvor stykke 2 er hele kagen og i (1,1) er det stykke 3, der er det hele.
På kanten mellem (0,0) og (0,1) er stykke nummer 1 “tomt”, og tilsvarende på de andre kanter.
I et punkt (x1,x2) vil spiller A måske foretrække stykke nummer 1, spiller B nummer 2 og spiller C måske også nummer 1. Der vil være en del af trekanten, hvori A vil foretrække 1, en anden del, hvor A foretrækker 2, og en tredie, hvor han foretrækker 3. (og nogen grænseområder, hvor han er ligeglad). Og tilsvarende for spillerne B og C. Nu skal man vise, at der findes et punkt, hvor spillerne foretrækker hver sit stykke. Og det kan man – med visse forudsætninger, men sådan er det jo i matematik. Ingrediensen i beviset er Brouwers fikspunktsætning, som har forbavsende mange anvendelser. Den siger:
En kontinuert afbildning fra en kugle til en kugle (tænk her på en klump modellervoks, som man kun må ælte og ikke flå) har et fikspunkt. (Et punkt er kommet tilbage, hvor det var)
Som illustration: Hvis man tager en blok papir, tager det øverste stykke af og krøller det sammen og lægger papirkuglen ovenpå blokken. Så vil der være et punkt, der ligger lige præcis lodret over der, hvor det var, før vi rev papiret af blokken.
Jeg vil ikke gengive, hvordan det bliver brugt i kageudskærings eksistensbeviset, men det står i artiklen.
Bemærk i øvrigt, problemet kan vendes om, så man skal dele noget, man ikke bryder sig om. Opvask og lignende. Det giver tilsvarende udskæringsalgoritmer “med modsat fortegn” i en vis forstand.
Hvad er det nye?
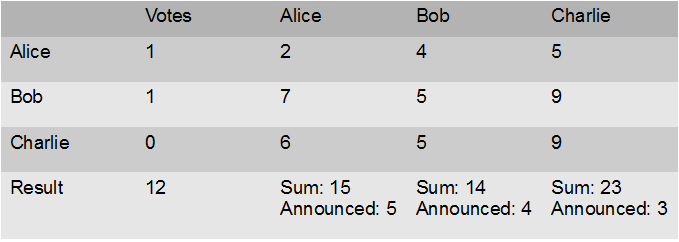
De to australiere har lavet en algoritme, som deler misundelsesfrit i endelig mange skridt. Er man kun 2, vil du deler, din søster vælger, være misundelsesfri. Men er man flere om det, bliver det mere vanskeligt, for den, der vælger sidst, kunne jo misunde en af dem, der valgte først. Den nye algoritme gør, for tilfældet med 3 personer, A,B, C følgende:
C deler i tre dele, X,Y,Z og A og B peger på det stykke, de helst vil have. Er det to forskellige stykker, er alt fint og C får det sidste.
Peger A og B på samme stykke, Z, sker følgende: B skærer så meget af dette stykke, at det, der er tilbage, Z’ er lige så meget værd – for hende! – som det, hun næsthelst ville have – lad os sige Y.
Læg det, der er skåret af til side. Lad A vælge. Hvis A ikke vælger Z’, er B tvunget til at tage det stykke. Vi har nu en misundelsesfri deling af kagen, bortset fra det, vi har lagt til side: A er tilfreds, da hun vælger først. B er tilfreds, da de to stykker, var lige meget værd. C er tilfreds, da de tre oprindelige stykker var lige meget værd. Vi har nu fordelt C fik X, B fik Y og A fik Z’ hvis ikke B blev tvunget til at tage Z’
Nu skal det afskårne deles (eller gives til hunden). Hvis A tog det tilrettede stykke, går det som følger:
B deler i tre dele. A vælger først, derefter C og til sidst B. Det er nu alt i alt misundelsesfrit. C har allerede fået X, der er lige så meget værd som Y og Z og derfor også lige så meget værd som Z’+det stykke A har fået i anden omgang. Derfor er C ikke misundelig på A. Og C vælger før B og er heller ikke misundelig på hende. B delte og er derfor tilfreds. A valgte først og er derfor glad. (Jeg indser nu, at det nok kan skrives smukt ned med uligheder mellem de forskelliges præferencefunktioner, men det kan I selv filosofere over.)
For flere “spillere”, bliver det en meget lang proces, hvor der skal byttes om på, hvem der vælger, tages hensyn til, om en delmængde af spillerne alle foretrækker samme stykke…



=P(A)P(B)")
 mulige udfald af vores eksperiment.
mulige udfald af vores eksperiment.

 tilfælde ud af de
tilfælde ud af de =(2^n-2)/2^n= 1-2^{1-n}")
=(n+1)/2^n=(n+1)2^{-n}") .
.=n/2^n=n\cdot 2^{-n}") for.
for.(n+1)2^{-n}")
(n+1)") udregne parenteser og reducer til
udregne parenteser og reducer til  . n=3 er en løsning og der er kun en løsning (venstresiden vokser eksponentielt og højresiden er en linje, så de skærer højst en gang).
. n=3 er en løsning og der er kun en løsning (venstresiden vokser eksponentielt og højresiden er en linje, så de skærer højst en gang).
=2^{n-2}+1") . E.Klein viste, at g(4)=5 ved at bevise, at alle konfigurationer af fem punkter er en af de tre (til venstre):
. E.Klein viste, at g(4)=5 ved at bevise, at alle konfigurationer af fem punkter er en af de tre (til venstre):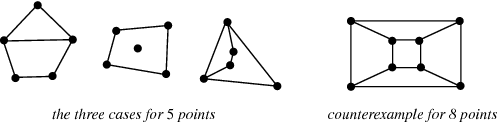


 ,
,  og
og  også.
også.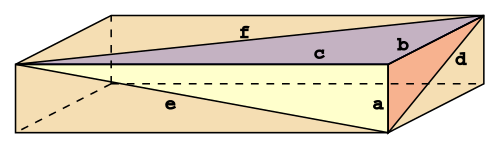
 og g er et helt tal.
og g er et helt tal. (påstår Wikipedia).
(påstår Wikipedia). . Men det tror jeg nu alligevel ikke, jeg skal…
. Men det tror jeg nu alligevel ikke, jeg skal…
 . Det er egentlig en meget smukkere konstruktion end Gervers. Men arealet er
. Det er egentlig en meget smukkere konstruktion end Gervers. Men arealet er  altså ca. 2,2074. Hammersley fandt også en øvre grænse for sofakonstanten på
altså ca. 2,2074. Hammersley fandt også en øvre grænse for sofakonstanten på  (ca. 2,82). Jeg har ikke læst argumentet for det, så det vil jeg ikke udbrede mig om, men interesserede kan som altid Google.
(ca. 2,82). Jeg har ikke læst argumentet for det, så det vil jeg ikke udbrede mig om, men interesserede kan som altid Google. mellem de to linjer? Og hvad har det med
mellem de to linjer? Og hvad har det med  at gøre?
at gøre? samt sinus og cosinus
samt sinus og cosinus som et vektorrum hvor hvert punkt r er entydigt beskrevet af to reelle koordinater x og y, eller r = [x; y]. Rummet
som et vektorrum hvor hvert punkt r er entydigt beskrevet af to reelle koordinater x og y, eller r = [x; y]. Rummet ^2+(y-y')^2}.")
:=\int_{t_0}^{t_1} \sqrt{(x'(t))^2+(y'(t))^2}dt")
 pa papiret og kald det [1; 0].
pa papiret og kald det [1; 0]. . Vi er nu klar til at gå i gang med at finde punktet med koordinater [0; 1] og derefter at tegne y-aksen.
. Vi er nu klar til at gå i gang med at finde punktet med koordinater [0; 1] og derefter at tegne y-aksen. = -g(t)") og
og  = f(t)") , hvor f(0) = 1
, hvor f(0) = 1 = f^2(t) + g^2(t)") må være konstant, fordi
må være konstant, fordi  = 0") for alle t, og derfor har vi, at
for alle t, og derfor har vi, at  = 1") for alle t. Vi konkluderer, at billedmængden af kurven r(t) = [f(t); g(t)] er en delmængde af enhedscirklen.
for alle t. Vi konkluderer, at billedmængden af kurven r(t) = [f(t); g(t)] er en delmængde af enhedscirklen. og
og  er periodiske. Vi ved, at
er periodiske. Vi ved, at \leq 1") og
og \leq 1") . Når
. Når  bliver kun lidt større end 0, er
bliver kun lidt større end 0, er ") stadigvæk tæt på 1, derfor positiv. Ligningen
stadigvæk tæt på 1, derfor positiv. Ligningen =f(t)") medfører til, at
medfører til, at =-g(t)<0") , at
, at  sådan at
sådan at =0") og
og =1") .
. , bliver
, bliver  mens
mens  . Det må eksistere et
. Det må eksistere et  sådan at
sådan at =-1") og
og =0") .
. bliver
bliver  sådan at
sådan at =0") og
og =-1") .
. , er
, er  . Det må eksistere et
. Det må eksistere et  sådan at
sådan at =1") og
og =0") .
.:=f(t+T)") og
og :=g(t+T)") løser det samme system som
løser det samme system som =f(t+T)") og
og =g(t+T)") . Det beviser, at
. Det beviser, at  er den mindste (positive) periode. Fra nu af, ændrer vi
er den mindste (positive) periode. Fra nu af, ændrer vi  ,
,  , og skriver
, og skriver  i stedet for
i stedet for :=\cos^2(t/2)-\sin^2(t/2)") og
og :=2\cos(t/2)\sin(t/2)") . Vi har, at
. Vi har, at  og
og  samt med
samt med =1") og
og =0") . Løsningens entydighed medfører igen at
. Løsningens entydighed medfører igen at =\cos(t)") og
og =\sin(t)") . Med andre ord:
. Med andre ord:=\cos^2(t/2)-\sin^2(t/2),\quad \sin(t)=2\cos(t/2)\sin(t/2).")
 ,
,  og
og  . Husk, at
. Husk, at =0") og
og =1") ,
, =-1") og
og =0") , mens
, mens =0") og
og =-1") . Perioden
. Perioden  er det mindste positivt tal hvor
er det mindste positivt tal hvor =1") og
og =0") .
. i ligningen ovenfor, har vi at:
i ligningen ovenfor, har vi at:=2 \cos(\pi) \sin(\pi),\quad 1=\cos(2\pi)=\cos^2(\pi)-\sin^2(\pi).")
") eller
eller ") må være nul. Hvis vi kobler det med den anden ligning, konkluderer vi, at
må være nul. Hvis vi kobler det med den anden ligning, konkluderer vi, at =0") og
og =\pm 1") . Men
. Men  og
og =-1") og
og :=-\cos(\pi-t)") og
og :=\sin(\pi-t)") . Vi ser, at
. Vi ser, at =-\cos(\pi-t),\quad \sin(t)=\sin(\pi-t).")
 i ligningen ovenfor. Det giver
i ligningen ovenfor. Det giver =-\cos(\pi/2)") , eller
, eller =0") . Men det eneste punkt mellem
. Men det eneste punkt mellem =\sin(t_1)=1") .
.:=\cos(-t)") og
og :=-\sin(-t)") . Igen igen
. Igen igen =\cos(-t),\quad \sin(t)=-\sin(-t).")
 i Ligning 3 og brug Ligning 4:
i Ligning 3 og brug Ligning 4:=\cos(-\pi/2)=-\cos(3\pi/2),\quad -1=-\sin(\pi/2)=\sin(-\pi/2)=\sin(3\pi/2).")
=\frac{\sin(t)}{\cos(t)}") for
for  . På det interval har vi, at
. På det interval har vi, at =\frac{1}{\cos^2(t)}>0") , funktionen er bijektiv og billedmængden er
, funktionen er bijektiv og billedmængden er  . Dens inverse noteres med
. Dens inverse noteres med  , er defineret på
, er defineret på ") , og
, og =\frac{1}{1+x^2}") .
.=\cos(\pi/4)=1/\sqrt{2}") og
og =1") og
og =\pi/4") . Derfor:
. Derfor:dx=4 \int_0^1 \frac{1}{1+x^2}dx.")


 :
:
^k}{2k+1} <\pi <4\sum_{k=0}^{2n} \frac{(-1)^k}{2k+1},\quad n\geq 0.")
 . Rækken blev først fundet omkring 1400 tallet af den indiske matematiker Madhava fra Sangamagrama, og senere genfundet af James Gregory i 1668.
. Rækken blev først fundet omkring 1400 tallet af den indiske matematiker Madhava fra Sangamagrama, og senere genfundet af James Gregory i 1668.![\mathbf{r}(t)=[\cos(t),\sin(t)]](https://s0.wp.com/latex.php?latex=%5Cmathbf%7Br%7D%28t%29%3D%5B%5Ccos%28t%29%2C%5Csin%28t%29%5D&bg=ffffff&fg=000000&s=0 "\mathbf{r}(t)=[\cos(t),\sin(t)]") . Vi har lige set, at når
. Vi har lige set, at når ![\mathbf{r}(0)=[1,0]](https://s0.wp.com/latex.php?latex=%5Cmathbf%7Br%7D%280%29%3D%5B1%2C0%5D&bg=ffffff&fg=000000&s=0 "\mathbf{r}(0)=[1,0]") til
til ") hvor
hvor  er givet ved formlen 1. Her husker vi igen, at
er givet ved formlen 1. Her husker vi igen, at =-y(t)") ,
, =x(t)") ,
, +y^2(t)=1") og derfor
og derfor )^2+(y'(t))^2=1") . Det giver:
. Det giver:=\theta,\quad L(0,\pi)=\pi.")
 og som går gennem
og som går gennem ![P=[1,0]](https://s0.wp.com/latex.php?latex=P%3D%5B1%2C0%5D&bg=ffffff&fg=000000&s=0 "P=[1,0]") . Cirklen krydser igen x-aksen i punktet
. Cirklen krydser igen x-aksen i punktet ![\mathbf{r}(\pi)=[-1,0]](https://s0.wp.com/latex.php?latex=%5Cmathbf%7Br%7D%28%5Cpi%29%3D%5B-1%2C0%5D&bg=ffffff&fg=000000&s=0 "\mathbf{r}(\pi)=[-1,0]") . Tag et stykke snor af længde
. Tag et stykke snor af længde  , og med et endepunkt i
, og med et endepunkt i ") . Vi har vist, at
. Vi har vist, at  , så er snoren lang nok til at nå punktet
, så er snoren lang nok til at nå punktet ") . Klip snoren således at et af stykkerne dækker den øvre halvcirkel fra
. Klip snoren således at et af stykkerne dækker den øvre halvcirkel fra ![\mathbf{r}(\pi/2)=[0,1]](https://s0.wp.com/latex.php?latex=%5Cmathbf%7Br%7D%28%5Cpi%2F2%29%3D%5B0%2C1%5D&bg=ffffff&fg=000000&s=0 "\mathbf{r}(\pi/2)=[0,1]") . Tegn y-aksen og drik en stor, sort kaffe.
. Tegn y-aksen og drik en stor, sort kaffe. hvor
hvor  og
og  er begge heltal. Men lad os antage det modsætte; det vil sige, vi antager at
er begge heltal. Men lad os antage det modsætte; det vil sige, vi antager at  hvor
hvor =\frac{1}{n!}x^n(a-bx)^n,\quad P_n(x)=p_n(x)-p_n''(x)+\ldots+(-1)^n p_n^{(2n)}(x),\quad n\geq 1.")
}(0)") er heltal. For eksempel, har vi at:
er heltal. For eksempel, har vi at:=\frac{1}{n!}(nx^{n-1}(a-bx)^n-nbx^n(a-bx)^{n-1})=\frac{1}{(n-1)!}x^{n-1}(a-bx)^{n-1}(x-b(a-bx)).")
") er nul hvis
er nul hvis  og
og ")
 hvis
hvis  . Hvis vi fortsætter med at differentiere, finder vi, at
. Hvis vi fortsætter med at differentiere, finder vi, at  , mens når
, mens når  , er de eneste ikke nul bidrag fra de forskellige led kun dem hvor vi har “differentieret væk” faktoren
, er de eneste ikke nul bidrag fra de forskellige led kun dem hvor vi har “differentieret væk” faktoren  . Det giver en
. Det giver en  som gør, at resultatet bliver et heltal.
som gør, at resultatet bliver et heltal.=p_n(a/b-x)") . Kædereglen siger, at
. Kædereglen siger, at }(a/b)=(-1)^jp_n^{(j)}(0)") , derfor er
, derfor er }(\pi)") også heltal, for alle
også heltal, for alle  . En vigtig konsekvens er, at både
. En vigtig konsekvens er, at både ") og
og ") er heltal.
er heltal.") ser vi, at
ser vi, at +P_n(x)=p_n(x)") . Derfor:
. Derfor:\sin(x)-P_n(x)\cos(x))'= P_n''(x)\sin(x)+P_n(x)\sin(x)=p_n(x)\sin(x).")
\sin(x)dx =P_n(\pi)+P_n(0),")
 . Funktionen
. Funktionen \sin(x)") er altid positiv på intervallet
er altid positiv på intervallet ") , derfor er dens integral også positiv ved siden af at være et heltal. Vi må have:
, derfor er dens integral også positiv ved siden af at være et heltal. Vi må have:\sin(x)dx, \quad {\rm for} \; {\rm all}\; n\geq 1.")
\sin(x)\leq \frac{ \pi^n a^n}{n!}") når
når  . Derfor,
. Derfor, \sin(x)dx\leq \frac{ \pi^{n+1} a^n}{n!}") . Men højresiden går mod nul når
. Men højresiden går mod nul når 
\geq (g2,s2,b2)") hvis
hvis \geq f(g2,s2,b2)") og så er der jo frit slag: Vælg en funktion
og så er der jo frit slag: Vælg en funktion  og brug ordningen af de reelle tal til at ordne punkter i rummet. Man vil jo nok kræve noget af funktionen h. Eksempelvis, at lande med lige mange guld og bronze, men forskelligt antal sølv bliver ranket efter, hvem der har flest sølvmedaljer.
og brug ordningen af de reelle tal til at ordne punkter i rummet. Man vil jo nok kræve noget af funktionen h. Eksempelvis, at lande med lige mange guld og bronze, men forskelligt antal sølv bliver ranket efter, hvem der har flest sølvmedaljer.
 eller omskrevet
eller omskrevet >B(s_2-s_1)+C(b_2-b_1)") . Worst case (eller med matematik, det, der vil medføre, at uligheden holder i alle andre situationer) må være g1=g2+1, s1=b1=0 og s2 og b2 maksimale (landet har vundet alle sølv og alle bronze…) Altså kræves
. Worst case (eller med matematik, det, der vil medføre, at uligheden holder i alle andre situationer) må være g1=g2+1, s1=b1=0 og s2 og b2 maksimale (landet har vundet alle sølv og alle bronze…) Altså kræves  , hvor
, hvor  er det totale antal sølvmedaljer og
er det totale antal sølvmedaljer og  det totale antal bronze.
det totale antal bronze. og
og  er f(g1,s1,b1)>f(g2,s2,b2), som igen er
er f(g1,s1,b1)>f(g2,s2,b2), som igen er >C(b_2-b_1)") og igen er der et worst case, nemlig hvor s1=s2+1 og b2 er maksimalt. Det giver
og igen er der et worst case, nemlig hvor s1=s2+1 og b2 er maksimalt. Det giver  .
.