Dette indlæg er motiveret af https://fredhohman.com/card-shuffling/.
Opdateret 24/6-2018 10:20: Links til Numb3rs-bloggen tilføjet.
Spillekort skal blandes. En gængs måde at gøre det på, er at dele kortbunken i to mindre bunker af (ca.) samme størrelse og mikse de to bunker fra bund til top. På engelsk hedder det et riffle shuffle. (Jeg kender ikke det danske navn for denne måde at blande på.) Man kan overveje hvor mange gange dette skal gøres for bunken “er godt nok blandet” (for en passende definition af det). 7 gange er tilsyneladende nok (hvis man gør det rigtigt osv.). En matematisk model for denne måde at blande på er Gilbert-Shannon-Reeds modellen. Ovre på Numb3rs-bloggen er der mere om spillekort og matematik i dette indlæg. Bemærk at videoen (“7 gange er tilsyneladende nok”) er med Persi Diaconis som også omtales i Numb3rs-indlægget.
En mere simpel måde at blande på, er at tage det øverste kort og indsætte det et tilfældigt sted i bunken. Og sådan fortsætter man. Man kan nu stille sig selv det samme spørgsmål: hvor mange gange skal man gøre dette for at kortbunken er blandet “nok” (jf. ovenfor)?
Man kan vise (se fx 7 gange er tilsyneladende nok / https://fredhohman.com/card-shuffling/), at man i gennemsnit skal gentage en sådan simpel blanding 235 gange for at kortbunken er blandet “nok”. En del af svaret er, at bunken er blandet “nok” når bundkortet (det nederste kort i bunken inden man går i gang med at blande) har nået toppen af bunken og også selv er blevet blandet (dvs. flyttet til et tilfældigt sted i bunken).
I dette indlæg skal vi se, hvordan man kan opnå viden om eksempelvis sådanne processer ved at få computeren til at simulere mange, mange af sådanne blandinger og så registrere interessante egenskaber ved hver realiserede blanding. Denne fremgangsmåde kaldes for Monte Carlo-metoder og er et kraftfuldt værktøj indenfor statistikken. Man kan med en beskrivelse af den datagenererende process finde egenskaber for processen ved at få computeren til at realisere processen mange, mange gange.
Teoretiske resultater er ekstremt vigtige af mange årsager. Men det betyder ikke, at det er den eneste måde at opnå viden om processer på. Med Monte Carlo-metoden kan man dels kontrollere de teoretiske resultater, men ofte kan man faktisk opnå resultater som kan virke umulige at opnå teoretisk.
I dette tilfælde vil vi bruge Monte Carlo-metoden til at dels at finde det gennemsnitlige antal gange man skal blande før bunken er godt nok blandet. Det kan man også relativt let finde teoretisk (se ovenfor). Men man kunne også være interesseret i at finde fraktiler i fordelingen af antal blandinger. Så kan angive, at man i 95% af tilfældene skal blande mellem L og U gange før at bunken er blandet “nok”.
Den letteste måde at lave sådanne simulationer er på computeren med en random number generator (RNG), der kan generere tilfældige tal. Ofte må man nøjes med pseudorandom number generator (PRNG), men det er som regel også tilstrækkeligt. Og så skal man bruge et interface til denne PRNG således man kan få nogle tilfældige tal i beskrivelsen af processen. Ovre på Numb3rs-bloggen er der mere om tilfældige tal i dette indlæg.
Jeg vil her bruge R, der er et helt programmeringsmiljø (inkl. programmeringssprog) hovedsageligt anvendt til statistik, big data, maskinlæring, kunstig intelligens, dataanalyse m.fl. Det er et rigtigt godt vækrtøj at have i sin værktøjskasse. Rstudio er et fint IDE (integrated development environment) til R. Nedenfor bruges R’s sample-funktion til at trække tilfældige tal.
(Helt til sidst i dette indlæg kan I finde den komplette R-kode. Nedenfor kommer koden med output.)
Først skal vi have repræsenteret kortbunken:
> # C: Clubs / klør
> # D: Diamonds / ruder
> # H: Hearts / hjerter
> # S: Spades / spar
> faces <- c("C", "D", "H", "S")
> nums <- c("A", 2:10, "J", "Q", "K")
>
> # Vores kortbunke: CA, C2, C2, ..., CQ, CK, DA, ..., DK, ...., SK
> # Denne genereres automatisk, men man kunne også gøre det manuelt:
> # pile_init <- c("CA", "C2") # Osv.
> pile_init <- unlist(lapply(faces, function(x) paste0(x, nums)))
>
> # De første 6 kort i bunken
> head(pile_init, n = 6)
[1] "CA" "C2" "C3" "C4" "C5" "C6"
>
> # De sidste 6 kort i bunken
> tail(pile_init, n = 6)
[1] "S8" "S9" "S10" "SJ" "SQ" "SK"
>
> # Antallet af kort i bunken
> length(pile_init)
[1] 52
Det er ikke så vigtigt hvordan bunken er blandet når vi går i gang. Vi skal egentlig bare holde styr på det sidste kort som her er “SK”.
Og så går vi i gang med at simulere 1,000 kortblandinger. Hver gang registrerer vi antallet af blandinger, der blev foretaget før bunken var blandet “nok”:
> # Funktion der simulerer én blanding
> simulate_process <- function() {
+ # Vi starter med en ny bunke
+ pile <- pile_init
+
+ # En tæller til antallet af blandinger
+ rifs <- 0
+
+ while (TRUE) {
+ # Registrer at der nu er bladet én gang mere
+ rifs <- rifs + 1
+
+ # Tilfældig position som topkortet skal hen til
+ top_pos <- sample(x = seq_along(pile), size = 1)
+
+ # Med sandsynlighed 1/52 ender det igen i toppen
+ if (top_pos == 1) {
+ #pile <- pile
+ } else if (top_pos == length(pile)) {
+ # Det kan også ende i bunden
+ pile <- c(pile[-1], pile[1])
+ } else {
+ # Eller et sted midt i mellem
+ pile <- c(pile[2:top_pos], pile[1], pile[-(1:top_pos)])
+ }
+
+ # Hvis topkortet er bundkortet;
+ # her kunne man også have skrevet
+ # if (pile[1] == "SK") {
+ # men dette virker også selvom man ændrer pile_init
+ if (pile[1] == pile_init[length(pile_init)]) {
+ break
+ }
+ }
+
+ # Topkortet (der er nu er det oprindelige bundkort)
+ # skal også blandes, men vi er ligeglade med hvor det ender
+ rifs <- rifs + 1
+
+ return(rifs)
+ }
>
> # Indstiller PRNG til samme tilstand for at kunne reproducere resultaterne
> set.seed(1)
>
> # Simulér processen 1,000 gange
> riffles <- replicate(1000, simulate_process())
>
> # De første 6 blandinger:
> head(riffles, n = 6)
[1] 249 191 205 280 189 314
>
> # Gennemsnittet af antal blandinger
> mean(riffles)
[1] 234.757
Som I kan se får vi også at der i gennemsnit skal 235 blandinger til.
Men vores simulationer gør os i stand til at finde og vise fordelingen af antal blandinger:
> # Estimer fordelingen
> rif_dens <- density(riffles)
>
> # Equal-tailed interval (begge haler har samme sandsynlighed)
> qs <- quantile(riffles, c(0.025, 0.975))
>
> # Find x-værdierne
> x1 <- min(which(rif_dens$x >= qs[1]))
> x2 <- max(which(rif_dens$x < qs[2]))
>
> # De centrale 95%
> rif_dens$x[c(x1, x2)]
[1] 144.2375 384.8943
>
> plot(rif_dens)
> polygon(x = c(rif_dens$x[c(x1, x1:x2, x2)]), y = c(0, rif_dens$y[x1:x2], 0), col = "gray")
> abline(v = mean(riffles), lty = 2)
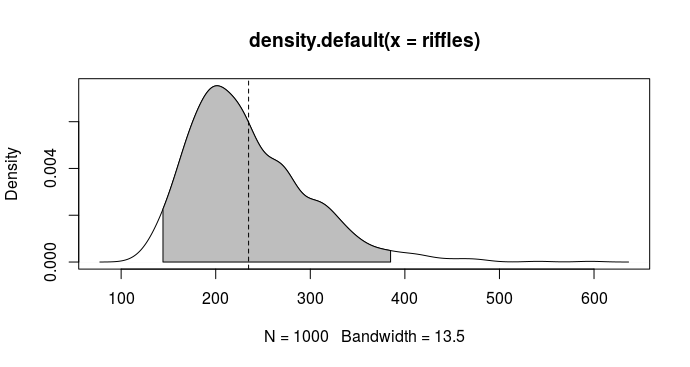
Altså vil man skulle forvente at skulle blande mellem 144 og 385 gange (og i gennemsnit 235) før at denne måde at blande på giver en bunke der er blandet nok.
(Hvilket nok er medvirkende til at jeg aldrig har set nogen praktisere denne form for kortblanding.)
Komplet R-kode:
# C: Clubs / klør
# D: Diamonds / ruder
# H: Hearts / hjerter
# S: Spades / spar
faces <- c("C", "D", "H", "S")
nums <- c("A", 2:10, "J", "Q", "K")
# Vores kortbunke: CA, C2, C2, ..., CQ, CK, DA, ..., DK, ...., SK
# Denne genereres automatisk, men man kunne også gøre det manuelt:
# pile_init <- c("CA", "C2") # Osv.
pile_init <- unlist(lapply(faces, function(x) paste0(x, nums)))
# De første 6 kort i bunken
head(pile_init, n = 6)
# De sidste 6 kort i bunken
tail(pile_init, n = 6)
# Antallet af kort i bunken
length(pile_init)
# Funktion der simulerer én blanding
simulate_process <- function() {
# Vi starter med en ny bunke
pile <- pile_init
# En tæller til antallet af blandinger
rifs <- 0
while (TRUE) {
# Registrer at der nu er bladet én gang mere
rifs <- rifs + 1
# Tilfældig position som topkortet skal hen til
top_pos <- sample(x = seq_along(pile), size = 1)
# Med sandsynlighed 1/52 ender det igen i toppen
if (top_pos == 1) {
#pile <- pile
} else if (top_pos == length(pile)) {
# Det kan også ende i bunden
pile <- c(pile[-1], pile[1])
} else {
# Eller et sted midt i mellem
pile <- c(pile[2:top_pos], pile[1], pile[-(1:top_pos)])
}
# Hvis topkortet er bundkortet;
# her kunne man også have skrevet
# if (pile[1] == "SK") {
# men dette virker også selvom man ændrer pile_init
if (pile[1] == pile_init[length(pile_init)]) {
break
}
}
# Topkortet (der er nu er det oprindelige bundkort)
# skal også blandes, men vi er ligeglade med hvor det ender
rifs <- rifs + 1
return(rifs)
}
# Indstiller PRNG til samme tilstand for at kunne reproducere resultaterne
set.seed(1)
# Simulér processen 1,000 gange
riffles <- replicate(1000, simulate_process())
# De første 6 blandinger:
head(riffles, n = 6)
# Gennemsnittet af antal blandinger
mean(riffles)
# Estimer fordelingen
rif_dens <- density(riffles)
# Equal-tailed interval (begge haler har samme sandsynlighed)
qs <- quantile(riffles, c(0.025, 0.975))
# Find x-værdierne
x1 <- min(which(rif_dens$x >= qs[1]))
x2 <- max(which(rif_dens$x < qs[2]))
# De centrale 95%
rif_dens$x[c(x1, x2)]
plot(rif_dens)
polygon(x = c(rif_dens$x[c(x1, x1:x2, x2)]), y = c(0, rif_dens$y[x1:x2], 0), col = "gray")
abline(v = mean(riffles), lty = 2)

 Hun har mere om det på sin blog Det er et af en længere række af yndlingsobjekter (favourite spaces – svært at oversætte)
Hun har mere om det på sin blog Det er et af en længere række af yndlingsobjekter (favourite spaces – svært at oversætte)

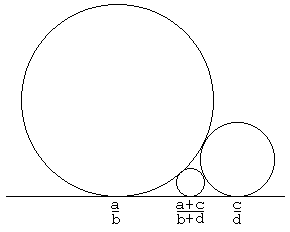
 og centrum i
og centrum i ") . Bed nu en anden om at gøre det samme – med nyt valg af p og q. De to cirkler vil tangere x-aksen og enten tangere hinanden eller ikke have noget til fælles. Bliv ved og der opstår et fint mønster af cirkler. De kaldes Ford-cirkler, fordi de blev beskrevet i en
. Bed nu en anden om at gøre det samme – med nyt valg af p og q. De to cirkler vil tangere x-aksen og enten tangere hinanden eller ikke have noget til fælles. Bliv ved og der opstår et fint mønster af cirkler. De kaldes Ford-cirkler, fordi de blev beskrevet i en  , så
, så  og dermed er x-koordinaten for centrum mellem 0 og 1. Tallet i cirklen er x-koordinaten for centrum (forkortet, så det svarer til p/q). Farven indikerer nævneren p.
og dermed er x-koordinaten for centrum mellem 0 og 1. Tallet i cirklen er x-koordinaten for centrum (forkortet, så det svarer til p/q). Farven indikerer nævneren p.
") så afstand mellem centrene opfylder
så afstand mellem centrene opfylder^2+(\frac{1}{2q^2}-\frac{1}{2s^2})^2")

 . Hvis de to cirkler skærer hinanden er
. Hvis de to cirkler skærer hinanden er  . Tangerer de, er
. Tangerer de, er  .
.^2+(\frac{1}{2q^2}-\frac{1}{2s^2})^2-(\frac{1}{2q^2}+\frac{1}{2s^2})^2") =
=^2- 4(\frac{1}{2q^22s^2})") =
=^2- (\frac{1}{q^2s^2})") =
=^2-1}{(qs)^2}")
^2 - 1<0") og altså
og altså ^2 <1")






 er uforkortelige brøker mellem 0 og 1 med nævner højst n. Rækkefølgen er efter størrelse. De elementer, der tilføjes til
er uforkortelige brøker mellem 0 og 1 med nævner højst n. Rækkefølgen er efter størrelse. De elementer, der tilføjes til  er medianten af naboerne:
er medianten af naboerne: tilføjes
tilføjes  . Naboerne er
. Naboerne er  . Medianten er dårlig brøkregning, Fareyplus:
. Medianten er dårlig brøkregning, Fareyplus:
 ligger medianten imellem dem
ligger medianten imellem dem  . Man viser det første ulighedstegn som følger:
. Man viser det første ulighedstegn som følger: 

a<(a+c)b \Leftrightarrow da<cb") og det følger af
og det følger af  .
. tilføjes i skridtet fra
tilføjes i skridtet fra  er højst n+1.
er højst n+1. er naboer. Antag
er naboer. Antag  og $\frac{q}{p}$ er uforkortelig. Så er p>k, da medianten ikke er i
og $\frac{q}{p}$ er uforkortelig. Så er p>k, da medianten ikke er i  . Altså er r=1.
. Altså er r=1. til
til  .
. og tilføjer medianter.
og tilføjer medianter.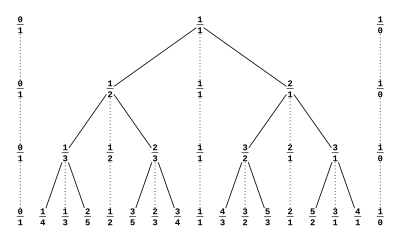
 er barn og forælder eller forælder og barn i træet (forbundet med en kant opad eller nedad fra
er barn og forælder eller forælder og barn i træet (forbundet med en kant opad eller nedad fra  til $latex \frac{c}{d}$, så er
til $latex \frac{c}{d}$, så er  . Bevis: Induktion. Det er ok for 0/1 og 1/1. Hvis ok for
. Bevis: Induktion. Det er ok for 0/1 og 1/1. Hvis ok for  eller opad
eller opad  .
.-a(b+d)=bc-ad=1") pr antagelse. Og tilsvarende for den anden side. (Lav selv et særargument for medianterne med hhv. 0/1 og 1/1.) En konsekvens er, at afstanden er
pr antagelse. Og tilsvarende for den anden side. (Lav selv et særargument for medianterne med hhv. 0/1 og 1/1.) En konsekvens er, at afstanden er  .
. . Omskriv de to uligheder til
. Omskriv de to uligheder til og
og  . Det er hele tal, så vi kan skrive
. Det er hele tal, så vi kan skrive  begge steder.
begge steder.(c+d)+(cq-dp)\geq c+d+a+b\geq p+q+1") (Det sidste følger af, at den ene brøk er fra niveau p+q)
(Det sidste følger af, at den ene brøk er fra niveau p+q)







 , hvor k er et naturligt tal. Det beviste Euler. Det er et eksempel på en reciprocitetslov – en egenskab ved primtallene udtrykkes ved division med rest . Her er det division med 4, som skal give rest 1. Vi skriver
, hvor k er et naturligt tal. Det beviste Euler. Det er et eksempel på en reciprocitetslov – en egenskab ved primtallene udtrykkes ved division med rest . Her er det division med 4, som skal give rest 1. Vi skriver 
 kaldes et Gaussisk heltal, hvis
kaldes et Gaussisk heltal, hvis  er hele tal. Hvis
er hele tal. Hvis  , så er
, så er (m-in)=p") ( husk,
( husk,  og så er resten givet ved at gange ind i paranteser) og omvendt. Et primtal p er et produkt af to Gausisske heltal hvis og kun hvis det er en sum af to kvadrattal.
og så er resten givet ved at gange ind i paranteser) og omvendt. Et primtal p er et produkt af to Gausisske heltal hvis og kun hvis det er en sum af to kvadrattal.  , hvor c og d er hele tal. Ganger, dividerer, adderer eller subtraherer man to Gaussiske rationale tal med hinanden, er resultatet rationalt. De Gaussiske rationale tal udgør derfor ikke bare en delmængde
, hvor c og d er hele tal. Ganger, dividerer, adderer eller subtraherer man to Gaussiske rationale tal med hinanden, er resultatet rationalt. De Gaussiske rationale tal udgør derfor ikke bare en delmængde ") af de komplekse tal, men et legeme. Man kan se det som en udvidelse af de rationale tal – man tilføjer
af de komplekse tal, men et legeme. Man kan se det som en udvidelse af de rationale tal – man tilføjer  og reglen
og reglen \to \mathbb{Q}(i)") , som er lineære: f((a+bi)+(c+di))=f(a+bi)+f(c+di) og bevarer produktstrukturen f((a+bi)(c+di))=f(a+bi)f(c+di) og desuden opfylder f(a+0i) = a+0i. Der er kun to afbildninger: Identitetsafbildningen f(a+bi)=a+bi og g(a+bi)=a-bi.
, som er lineære: f((a+bi)+(c+di))=f(a+bi)+f(c+di) og bevarer produktstrukturen f((a+bi)(c+di))=f(a+bi)f(c+di) og desuden opfylder f(a+0i) = a+0i. Der er kun to afbildninger: Identitetsafbildningen f(a+bi)=a+bi og g(a+bi)=a-bi. .
. og dermed kvadratrødder af alle negative rationale kvadrattal. Vi ved, at alle andengradspolynomier
og dermed kvadratrødder af alle negative rationale kvadrattal. Vi ved, at alle andengradspolynomier  med rationale a,b,c, har to rødder (mere præcist, kan skrives
med rationale a,b,c, har to rødder (mere præcist, kan skrives (x-r_2)") med
med ") og en formel for disse rødder kan skrives blot med brug af kvadratrodssymbolet.
og en formel for disse rødder kan skrives blot med brug af kvadratrodssymbolet. har rødder, som kan opskrives ved brug af kvadratrødder og kubikrødder. Tilsvarende for 4.gradspolynomier, når man tilføjer fjerde rødder. Men for femtegradspolynomier går det galt. Det viste Abel og Galois. Det er altså ikke nok at kunne løse ligninger
har rødder, som kan opskrives ved brug af kvadratrødder og kubikrødder. Tilsvarende for 4.gradspolynomier, når man tilføjer fjerde rødder. Men for femtegradspolynomier går det galt. Det viste Abel og Galois. Det er altså ikke nok at kunne løse ligninger  for at kunne løse alle femtegradspolynomieligninger. Det mere generelle spørgsmål er, om der er en sammenhæng mellem løsninger til et polynomium
for at kunne løse alle femtegradspolynomieligninger. Det mere generelle spørgsmål er, om der er en sammenhæng mellem løsninger til et polynomium ") og et andet
og et andet ") .
. , hvis
, hvis  og
og  , hvis
, hvis  . Funktionen
. Funktionen  kaldes en Frobeniusafbildning og er et element af Galoisgruppen. Frobeniusafbildningen er forbindelsen mellem “kan man skrive p som en sum af to kvadrattal” og “hvad er
kaldes en Frobeniusafbildning og er et element af Galoisgruppen. Frobeniusafbildningen er forbindelsen mellem “kan man skrive p som en sum af to kvadrattal” og “hvad er  “.
“. har rod 1, når man regner modulo 3, da
har rod 1, når man regner modulo 3, da  . Men 1 er ikke en rod modulo 5. Hvor meget information er der i, at kende antallet af rødder modulo primtal? Og hvad har det med Galoisgrupper at gøre?
. Men 1 er ikke en rod modulo 5. Hvor meget information er der i, at kende antallet af rødder modulo primtal? Og hvad har det med Galoisgrupper at gøre?
 Og naturligvis udbud og efterspørgsel:
Og naturligvis udbud og efterspørgsel:  og
og  .
.") for at indikere at efterspørgslen idag afhænger af prisen idag. Men udbuddet af grise kan ikke afhænge af prisen idag. Den kendte griseavleren ikke, da hun besluttede, hvor mange grise, der skulle produceres. Med en passende periode (den tid, det tager at få en gris klar til salg) kan vi skrive
for at indikere at efterspørgslen idag afhænger af prisen idag. Men udbuddet af grise kan ikke afhænge af prisen idag. Den kendte griseavleren ikke, da hun besluttede, hvor mange grise, der skulle produceres. Med en passende periode (den tid, det tager at få en gris klar til salg) kan vi skrive ") – udbuddet idag afhænger af prisen i forrige periode.
– udbuddet idag afhænger af prisen i forrige periode. og
og  ? Las os gå ud fra, de er differentiable funktioner af en variabel
? Las os gå ud fra, de er differentiable funktioner af en variabel  , hvor input er pris og output er mængden af grisekød – i kilo eller en anden passende enhed. Højere pris giver mindre efterspørgsel og mere udbud, så
, hvor input er pris og output er mængden af grisekød – i kilo eller en anden passende enhed. Højere pris giver mindre efterspørgsel og mere udbud, så <0") og
og  >0") . Der er eksempler på varer, hvor det ikke er rigtigt – basale fødevarer, som er forholdsvis billige er et eksempel. Men det er en model, så nu går vi med den.
. Der er eksempler på varer, hvor det ikke er rigtigt – basale fødevarer, som er forholdsvis billige er et eksempel. Men det er en model, så nu går vi med den.
 og sætter gang i produktion af
og sætter gang i produktion af =Q_2") grise. De udbydes til salg og man må forestille sig en slags auktion, hvor der nu er
grise. De udbydes til salg og man må forestille sig en slags auktion, hvor der nu er  grise, som give prisen
grise, som give prisen ") .
.=Q_3") grise til salg. De går til prisen
grise til salg. De går til prisen  . Fortsætter man pilene rundt, kan man se, prisen svinge ind mod den pris, der svarer til skæringspunktet mellem de to kurver – den kaldes ligevægtsprisen.
. Fortsætter man pilene rundt, kan man se, prisen svinge ind mod den pris, der svarer til skæringspunktet mellem de to kurver – den kaldes ligevægtsprisen.
 og altså
og altså =g(p_{n-1})") . Nu simplificerer vi yderligere og lader begge funktioner være lineære:
. Nu simplificerer vi yderligere og lader begge funktioner være lineære:=a+bx") og
og =c+dx") , hvor
, hvor  og
og  . c kan godt være negativ – måske produceres der ikke grise, hvis prisen er for lav.) Så bliver ligningen
. c kan godt være negativ – måske produceres der ikke grise, hvis prisen er for lav.) Så bliver ligningen  , som kan omskrives til
, som kan omskrives til
 .
.") med
med  og omskriver til
og omskriver til ")
 . Løsningen er $latex y_n=(-k)^nA$ – det er ikke svært at se, at det er en løsning, uanset A, og at der ikke er andre. (Et induktionsbevis kan gøre det. Ikke noget fancy som for differentialligninger.)
. Løsningen er $latex y_n=(-k)^nA$ – det er ikke svært at se, at det er en løsning, uanset A, og at der ikke er andre. (Et induktionsbevis kan gøre det. Ikke noget fancy som for differentialligninger.)") er konstant, har vi fundet ligevægtsløsningen
er konstant, har vi fundet ligevægtsløsningen  .
.^n+\bar{y}")
 og får
og får^n+\bar{p}")
 , vil $p_n$ svinge omkring
, vil $p_n$ svinge omkring  . Hvis
. Hvis  svinger det ind mod
svinger det ind mod  svinger det frem og tilbage mellem de samme to værdier (grafen i midten nedenfor) og
svinger det frem og tilbage mellem de samme to værdier (grafen i midten nedenfor) og  giver svingning væk fra ligevægten. Man kan selvfølgelig finde
giver svingning væk fra ligevægten. Man kan selvfølgelig finde  , hvis man kender en begyndelsesbetingelse. Kender man
, hvis man kender en begyndelsesbetingelse. Kender man  , er
, er 

 være bevismaterialet (
være bevismaterialet ( er hypotesen at DNA profilen stammer fra Afrika, mens
er hypotesen at DNA profilen stammer fra Afrika, mens  er hypotesen at profilen stammer fra Europa. I forhold til at vurdere om bevismaterialet taler for et europæisk ophav frem for et afrikansk, kan vi bestemme likelihood ratioet,
er hypotesen at profilen stammer fra Europa. I forhold til at vurdere om bevismaterialet taler for et europæisk ophav frem for et afrikansk, kan vi bestemme likelihood ratioet,  ,
,}{P(E \mid H_A)},")
") er sandsynligheden for
er sandsynligheden for ") hvis
hvis  betyder det at det er titusind gange mere sandsynligt at se profilen i den europæsiske population frem for den afrikanske.
betyder det at det er titusind gange mere sandsynligt at se profilen i den europæsiske population frem for den afrikanske. = 10^{-2} = 0.01") mens i Europa
mens i Europa  og Afrika er
og Afrika er  (således at $LR_{EA} = 10^{4}$). Idet vi konkret ikke kender til den Grønlandske hyppighed (vi antager at vi ikke har en stikprøve derfra) kan vi ikke bestemme hyppigheden relativt i forhold til den grønlandske.
(således at $LR_{EA} = 10^{4}$). Idet vi konkret ikke kender til den Grønlandske hyppighed (vi antager at vi ikke har en stikprøve derfra) kan vi ikke bestemme hyppigheden relativt i forhold til den grønlandske.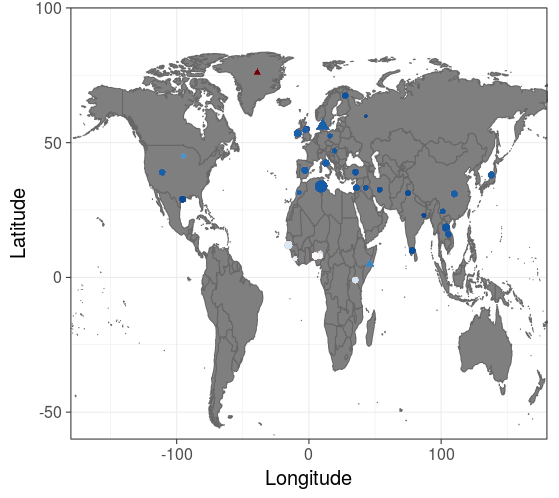
 = 10^{-37}") hvor de nærmeste populationer har hyppigheder omkring
hvor de nærmeste populationer har hyppigheder omkring  . Altså er profilen omkring
. Altså er profilen omkring  mere sandsynlig i Grønland i forhold til disse populationer.
mere sandsynlig i Grønland i forhold til disse populationer.
 ’te gæst, som tager
’te gæst, som tager  , er
, er 

 kubikmeter bagage. Kan alle gæsternes bagage være i ét (endeligt) stort rum? Vi kan begynde med at se lidt på, hvor meget plads de første
kubikmeter bagage. Kan alle gæsternes bagage være i ét (endeligt) stort rum? Vi kan begynde med at se lidt på, hvor meget plads de første  gæsters bagage fylder, hvor
gæsters bagage fylder, hvor  er et eller andet (stort) tal. Kald det samlede antal kubikmeter for
er et eller andet (stort) tal. Kald det samlede antal kubikmeter for  , så har vi at:
, så har vi at:+(\frac{1}{3}+\frac{1}{4})+(\frac{1}{5}+\frac{1}{6})+\dotsb+(\frac{1}{2N-1}+\frac{1}{2N})\end{array}")
 , for
, for  . Vi får derfor følgende vurdering.
. Vi får derfor følgende vurdering.+(\frac{1}{3}+\frac{1}{4})+(\frac{1}{5}+\frac{1}{6})+\dotsb+(\frac{1}{2N-1}+\frac{1}{2N})\\&>\frac{1}{2}+\frac{1}{1}+\frac{1}{2}+\frac{1}{3}+\dotsb+\frac{1}{N}=\frac{1}{2}+S_N,\end{array}")
 er det samlede antal kubikmeter for de første
er det samlede antal kubikmeter for de første  ,
, kubikmeter, løber vi tør efter
kubikmeter, løber vi tør efter  fordoblinger. Den førnævnte velopdragne matematiker ville skrive
fordoblinger. Den førnævnte velopdragne matematiker ville skrive
 , når
, når  . Grunden til at
. Grunden til at  er endelig mens
er endelig mens  er uendelig, er kort fortalt at
er uendelig, er kort fortalt at  går hurtigere mod
går hurtigere mod 
 , hvor
, hvor  betegner det
betegner det  ,
, er en potens mellem
er en potens mellem  uanset
uanset  (i hvertfald så længe
(i hvertfald så længe  ). Produktet kunne også skrives
). Produktet kunne også skrives  , hvor produkttegnet
, hvor produkttegnet  defineres ved
defineres ved  . Vi illustrerer med de første fire naturlige tal:
. Vi illustrerer med de første fire naturlige tal:
(p_2^0+p_2^1+\dotsb+p_2^N)\dotsb(p_N^0+p_N^1+\dotsb+p_N^N).")
 , hvor
, hvor  , som blot er summen af alle tal mellem
, som blot er summen af alle tal mellem  og
og 
 , så får vi
, så får vi 
 , så summen giver
, så summen giver  , hvis vi tager
, hvis vi tager  med også). Man kan vise, at der generelt gælder, at
med også). Man kan vise, at der generelt gælder, at
 . En sådan sum kaldes en geometrisk række og behandles bl.a. i
. En sådan sum kaldes en geometrisk række og behandles bl.a. i  , hvor der er
, hvor der er  gryde suppe, og første gæst tager 1/3 gryde, dvs. 2/3 af grydens indhold, hvorefter der er
gryde suppe, og første gæst tager 1/3 gryde, dvs. 2/3 af grydens indhold, hvorefter der er  tilbage, næste gæst tager 2/3 af grydens indhold, dvs.
tilbage, næste gæst tager 2/3 af grydens indhold, dvs.  osv. (Generelt kan man betragte en gryde, som til at begynde med er
osv. (Generelt kan man betragte en gryde, som til at begynde med er  fyldt og hvor hver gæst tager
fyldt og hvor hver gæst tager  af, hvad der er tilbage: det svarer til, at første gæst tager
af, hvad der er tilbage: det svarer til, at første gæst tager  grydefuld, anden gæst tager
grydefuld, anden gæst tager  osv. og efter uendeligt mange gæster er der intet tilbage). Vi ser nu, at
osv. og efter uendeligt mange gæster er der intet tilbage). Vi ser nu, at
 , så er
, så er  (prøv evt. selv at bevise dette eller nøjes med at konstatere det på en grafisk lommeregner), og da alle primtal netop er større eller lig
(prøv evt. selv at bevise dette eller nøjes med at konstatere det på en grafisk lommeregner), og da alle primtal netop er større eller lig  , så fås:
, så fås:
 . Vi er nu ved vejs ende: Venstre side går mod
. Vi er nu ved vejs ende: Venstre side går mod  opløftet i
opløftet i 

") Jeg har 7 punkter med hver 3 koordinater; hver søjle er koordinaterne for et punkt. Jeg har valgt dem, så middelværdien af hver af koordinaterne er 0. Er den ikke det, skal man trække middelværdien fra. Så nu er Origo, (0,0,0), midt i min datasky. I eksemplet med DNA har de en 200.000 x 1000 matrix.
Jeg har 7 punkter med hver 3 koordinater; hver søjle er koordinaterne for et punkt. Jeg har valgt dem, så middelværdien af hver af koordinaterne er 0. Er den ikke det, skal man trække middelværdien fra. Så nu er Origo, (0,0,0), midt i min datasky. I eksemplet med DNA har de en 200.000 x 1000 matrix. , covariansmatricen. Det giver en 3×3 matrix
, covariansmatricen. Det giver en 3×3 matrix")
") ,
, ") ,
, ")
 . Den første værdi er, som man kan se, langt større end de andre. Altså
. Den første værdi er, som man kan se, langt større end de andre. Altså 
 . Man mister ikke megen information ved kun at se på datapunkternes projektion ind på den retning.
. Man mister ikke megen information ved kun at se på datapunkternes projektion ind på den retning.
{kind=link}